4.8 Specifying Null Hypotheses in SPSS
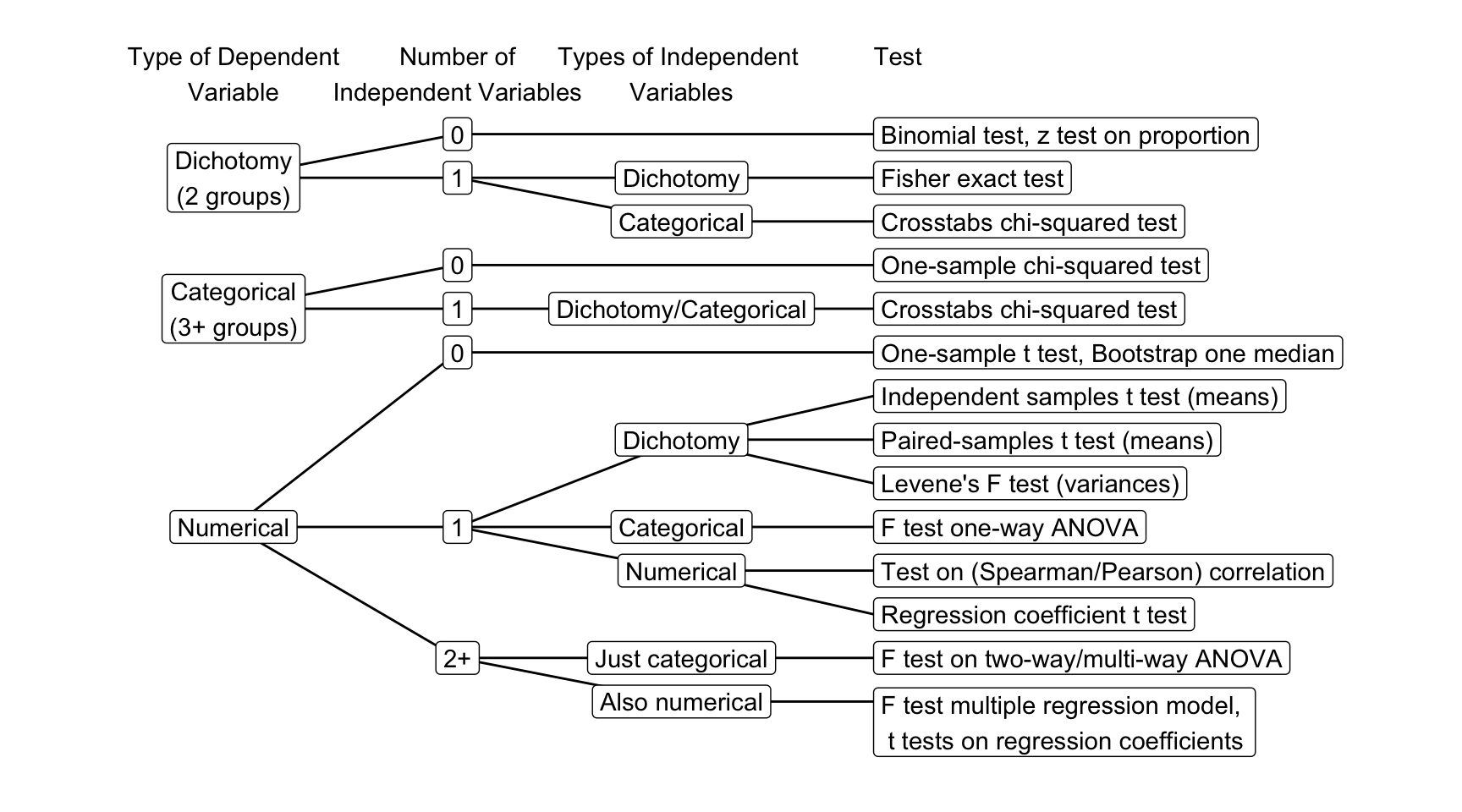
Figure 4.9: Flow chart for selecting a test in SPSS.
Statistics such as means, proportions, variances, and correlations are calculated on variables. For translating a research hypothesis into a statistical hypothesis, the researcher has to recognize the dependent and independent variables addressed by the research hypothesis and their variable types. The main distinction is between dichotomies (two groups), (other) categorical variables (three or more groups), and numerical variables. Once you have identified the variables, the flow chart in Figure 4.9 helps you to identify the right statistical test.
If possible, SPSS uses a theoretical probability distribution to approximate the sampling distribution. It will select the appropriate sampling distribution. In some cases, such as a test on a contingency table with two rows and two columns, SPSS automatically includes an exact test because the theoretical approximation cannot be relied on.
SPSS does not allow the user to specify the null hypothesis of a test if the test involves two or more variables. If you cannot specify the null hypothesis, SPSS uses the nil hypothesis that the population value of interest is zero. For example, SPSS tests the null hypothesis that males and females have the same average willingness to donate to a charity, that is, the mean difference is zero, if we apply an independent samples t test.
Imagine that we know from previous research that females tend to score one point higher on the willingness scale than males. It would not be very interesting to reject the nil hypothesis. Instead, we would like to test the null hypothesis that the average difference between females and males is 1.00. We cannot change the null hypothesis of a t test in SPSS, but we can use the confidence interval to test this null hypothesis as explained in Section 4.6.1.
In SPSS, the analyst has to specify the null hypothesis in tests on one variable, namely tests on one proportion, one mean, or one categorical variable. The following instructions explain how to do this.
4.8.1 Specify null for binomial test
A proportion is the statistic best suited to test research hypotheses addressing the share of a category in the population. The hypothesis that a television station reaches half of all households in a country provides an example. All households in the country constitute the population. The share of the television station is the proportion or percentage of all households watching this television station.
If we have a data set for a sample of households containing a variable indicating whether or not a household watches the television station, we can test the research hypothesis with a binomial test. The statistical null hypothesis is that the proportion of households watching the television station is 0.5 in the population.
Figure 4.10: A binomial test on a single proportion in SPSS.
We can also be interested in more than one category, for instance, in which regions are the households located: in the north, east, south, and west of the country? This translates into a statistical hypothesis containing two or more proportions in the population. If 30% of households in the population are situated in the west, 25 % in the south and east, and 20% in the north, we would expect these proportions in the sample if all regions are equally well-represented. Our statistical hypothesis is actually a relative frequency distribution, such as, for instance, in Table 4.1.
| Region | Hypothesized Proportion |
|---|---|
| North | 0.20 |
| East | 0.25 |
| South | 0.25 |
| West | 0.30 |
A test for this type of statistical hypothesis is called a one-sample chi-squared test. It is up to the researcher to specify the hypothesized proportions for all categories. This is not a simple task: What reasons do we have to expect particular values, say a region’s share of thirty per cent of all households instead of twenty-five per cent?
The test is mainly used if researchers know the true proportions of the categories in the population from which they aimed to draw their sample. If we try to draw a sample from all citizens of a country, we usually know the frequency distribution of sex, age, educational level, and so on for all citizens from the national bureau of statistics. With the bureau’s information, we can test if the respondents in our sample have the same distribution with respect to sex, age, or educational level as the population from which we tried to draw the sample; just use the official population proportions in the null hypothesis.
If the proportions in the sample do not differ more from the known proportions in the population than we expect based on chance, the sample is representative of the population in the statistical sense (see Section 1.2.6). As always, we use the p value of the test as the probability of obtaining our sample or a sample that is even more different from the null hypothesis, if the null hypothesis is true. Note that the null hypothesis now represents the (distribution in) the population from which we tried to draw our sample. We conclude that the sample is representative of this population in the statistical sense if we can not reject the null hypothesis, that is, if the p value is larger than .05. Not rejecting the null hypothesis means that we have sufficient probability that our sample was drawn from the population that we wanted to investigate. We can now be more confident that our sample results generalize to the population that we meant to investigate.
Figure 4.11: A chi-squared test on a frequency distribution in SPSS.
Finally, we have the significance test on one mean, which we have used in the example of average media literacy throughout this chapter. For a numeric (interval or ratio measurement level) variable such as the 10-point scale in this example, the mean is a good measure of the distribution’s center. Our statistical hypothesis would be that average media literacy score of all children in the population is (below) 5.5.
Figure 4.12: A one-sample t test in SPSS.