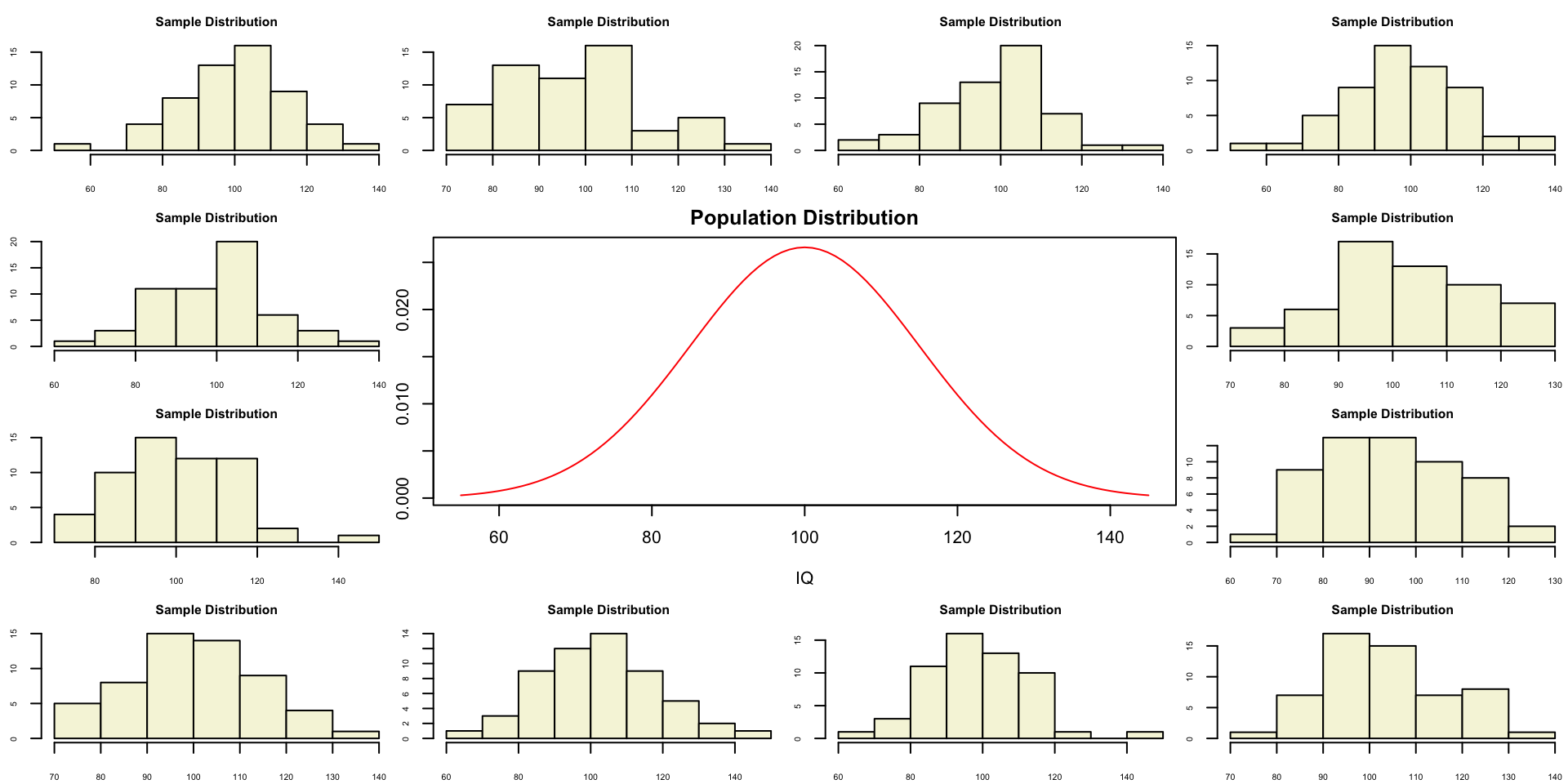
layout(matrix(c(2:6,1,1,7:8,1,1,9:13), 4, 4))
n = 56 # Sample size
df = n - 1 # Degrees of freedom
mu = 100
sigma = 15
IQ = seq(mu-45, mu+45, 1)
par(mar=c(4,2,2,0))
plot(IQ, dnorm(IQ, mean = mu, sd = sigma), type='l', col="red", main = "Population Distribution")
n.samples = 12
for(i in 1:n.samples) {
par(mar=c(2,2,2,0))
hist(rnorm(n, mu, sigma), main="Sample Distribution", cex.axis=.5, col="beige", cex.main = .75)
}T-distribution &
Multiple regression
University of Amsterdam
20 sep 2022
Gosset

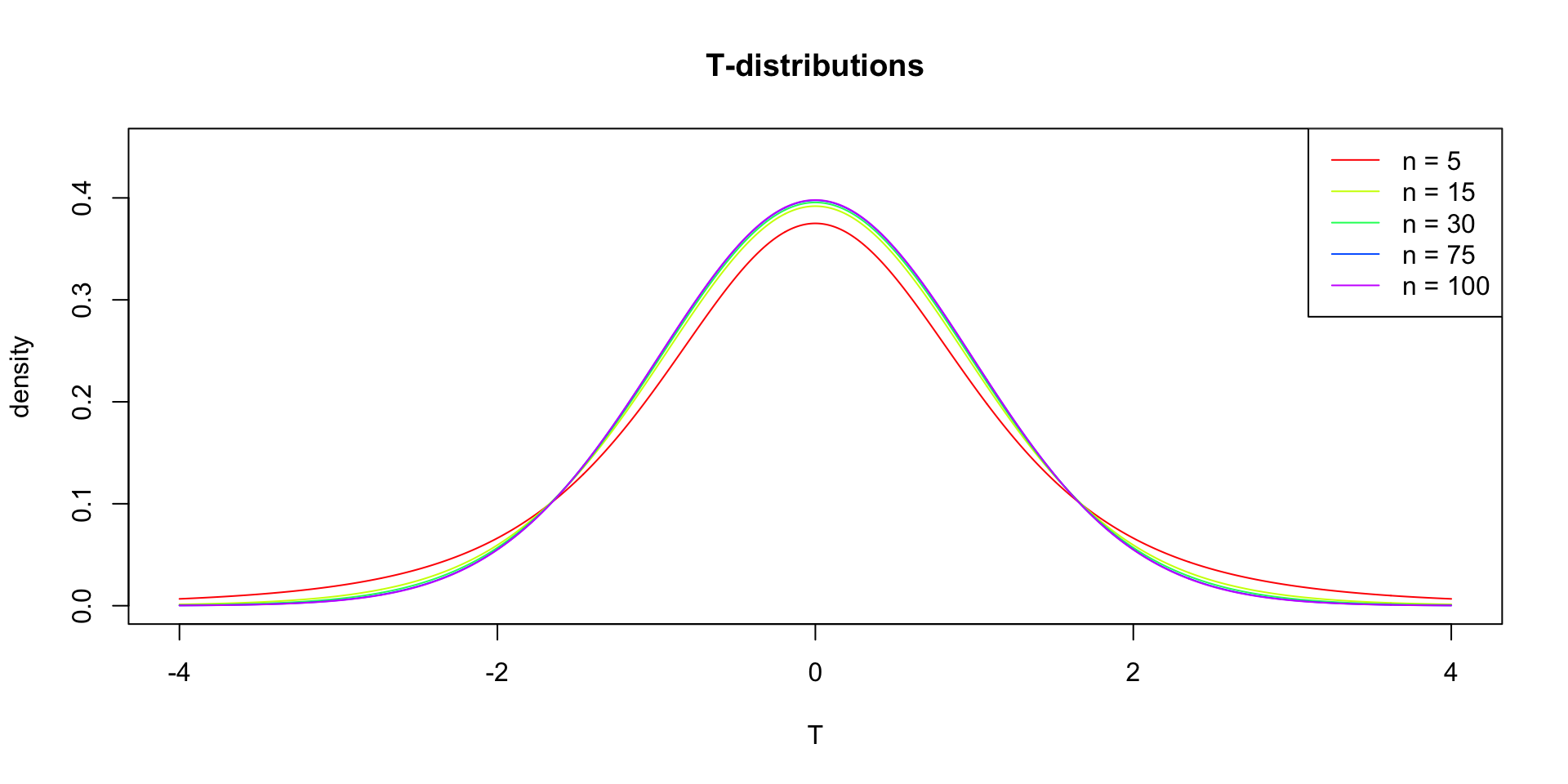
In probability and statistics, Student’s t-distribution (or simply the t-distribution) is any member of a family of continuous probability distributions that arises when estimating the mean of a normally distributed population in situations where the sample size is small and population standard deviation is unknown.
In the English-language literature it takes its name from William Sealy Gosset’s 1908 paper in Biometrika under the pseudonym “Student”. Gosset worked at the Guinness Brewery in Dublin, Ireland, and was interested in the problems of small samples, for example the chemical properties of barley where sample sizes might be as low as 3.
Source: Wikipedia
Population distribution
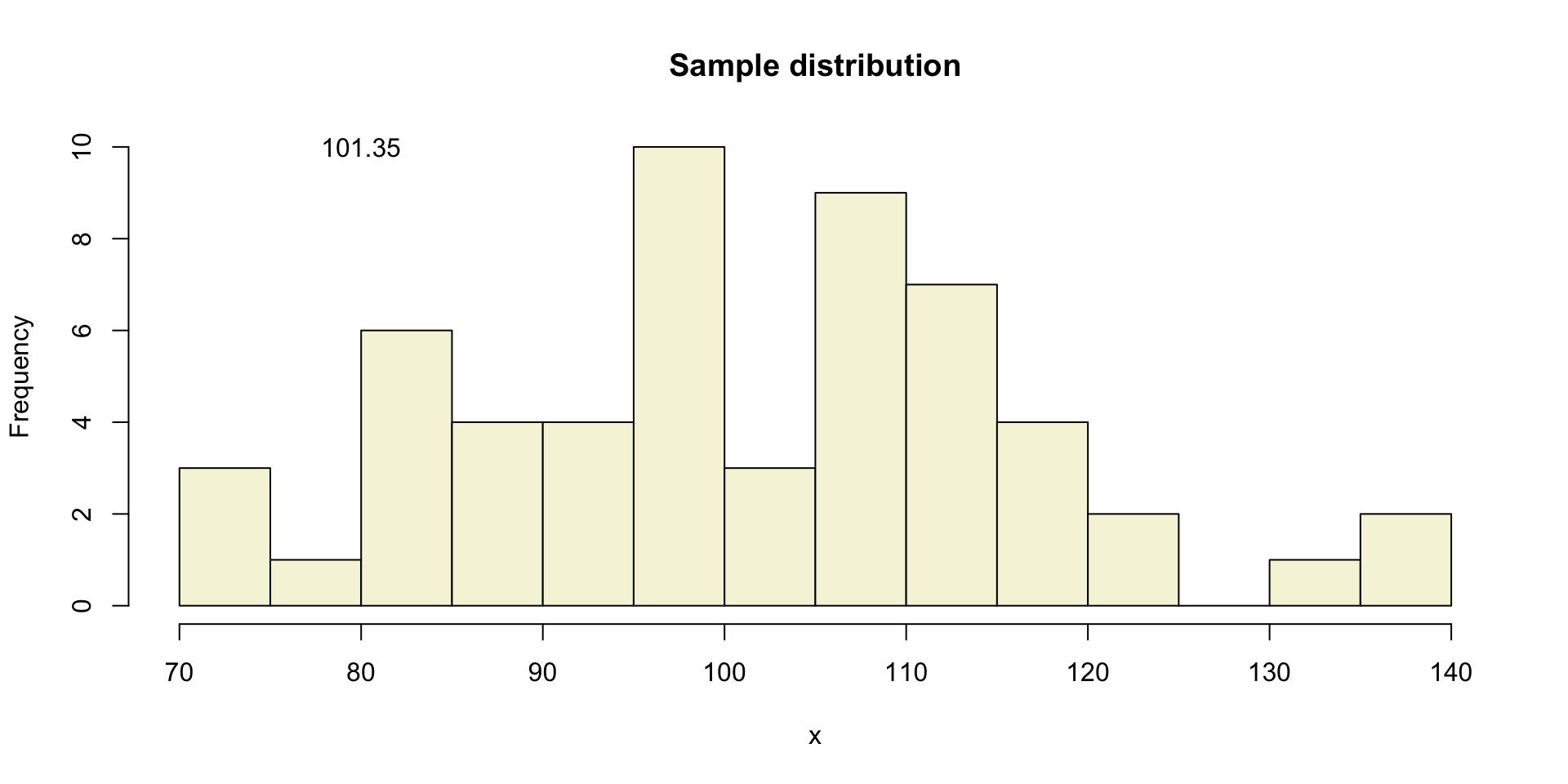
A sample
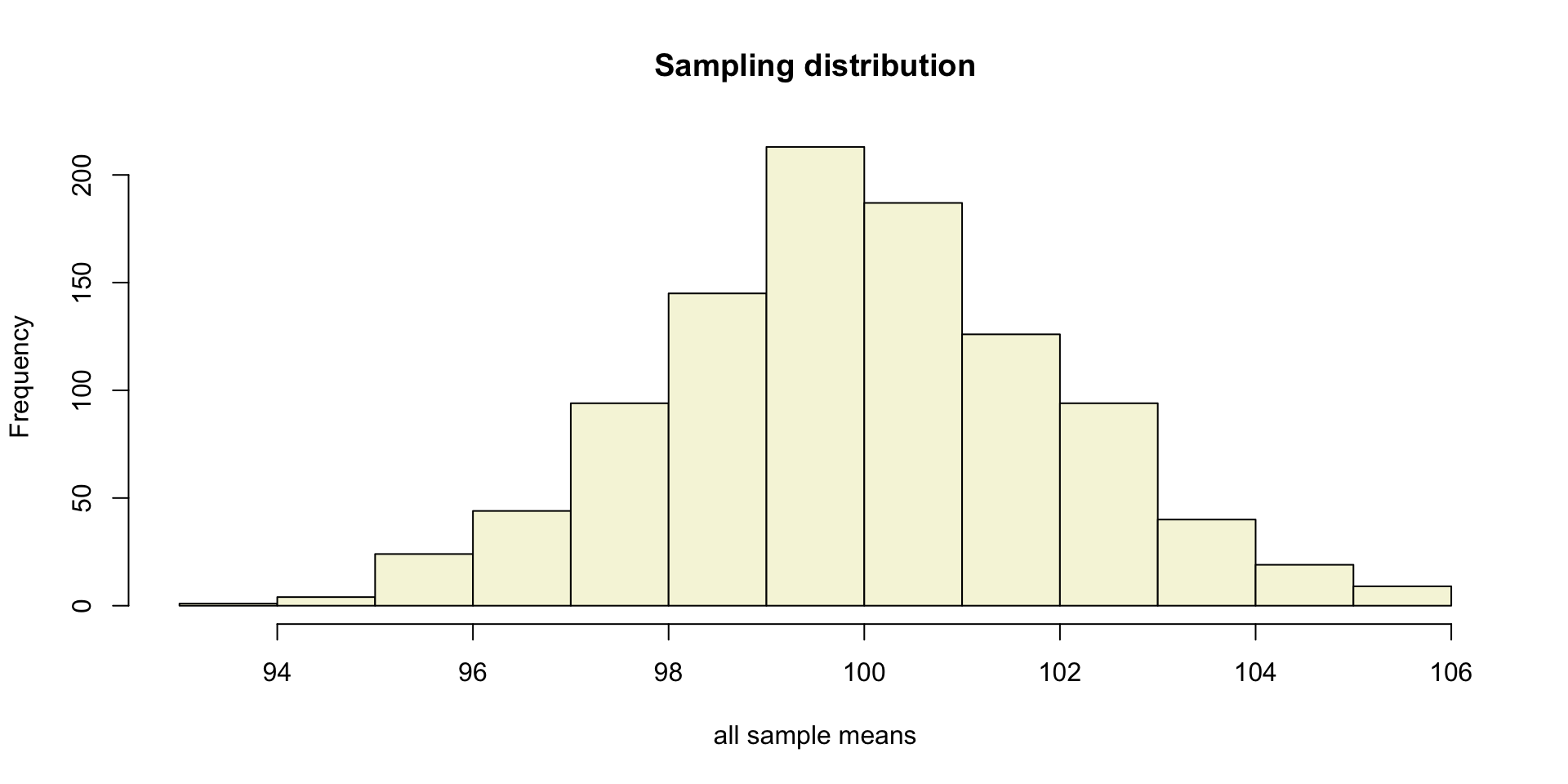
Sampling distribution
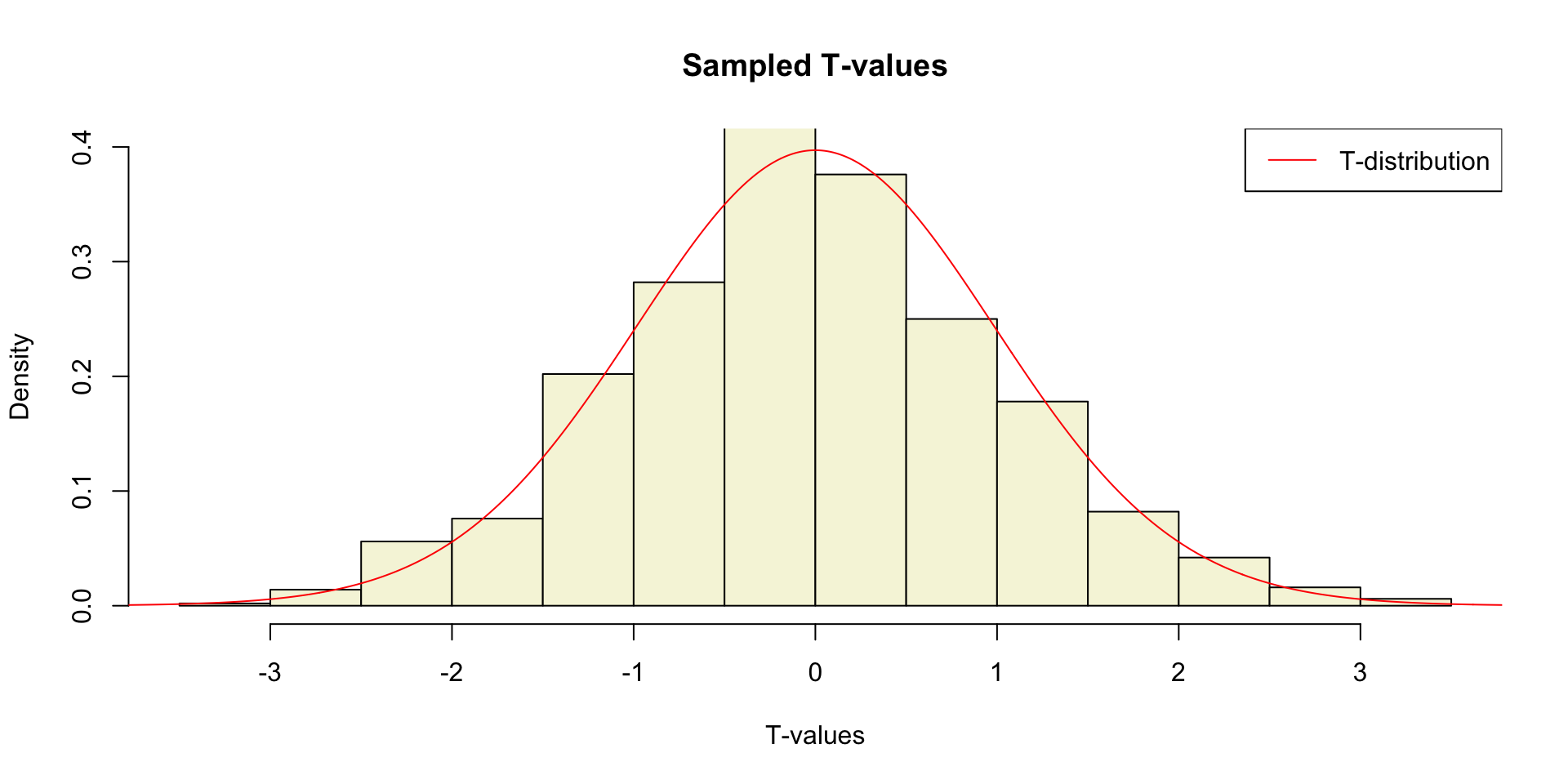
Sampled t-values
Effect-size distribution
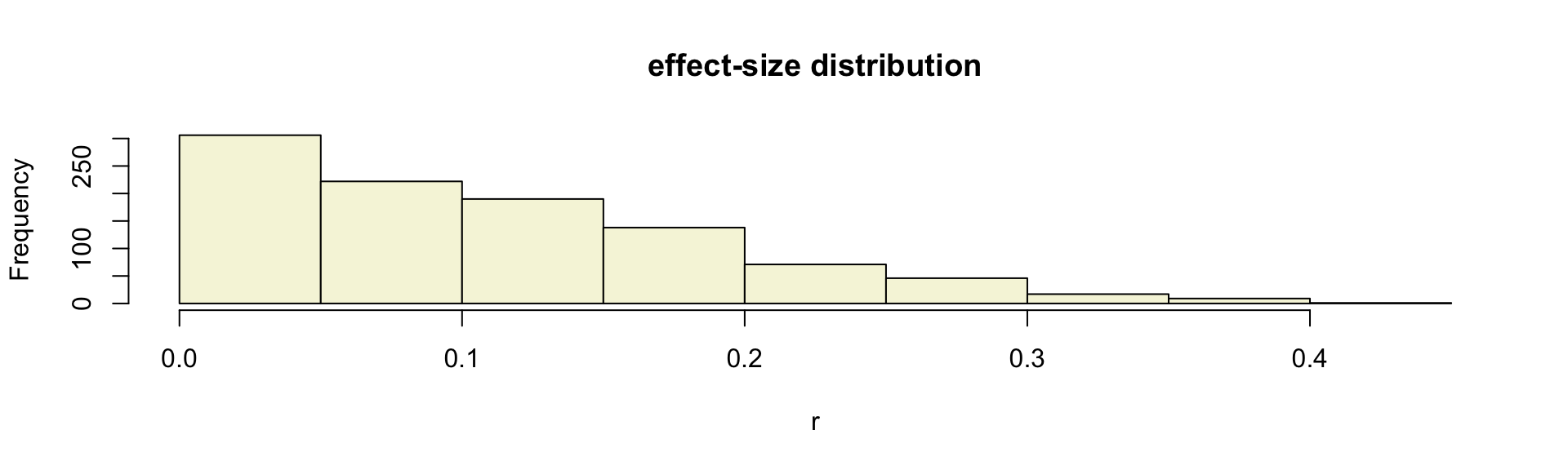
Cohen (1988)
- Small: \(0 \leq .1\)
- Medium: \(.1 \leq .3\)
- Large: \(.3 \leq .5\)
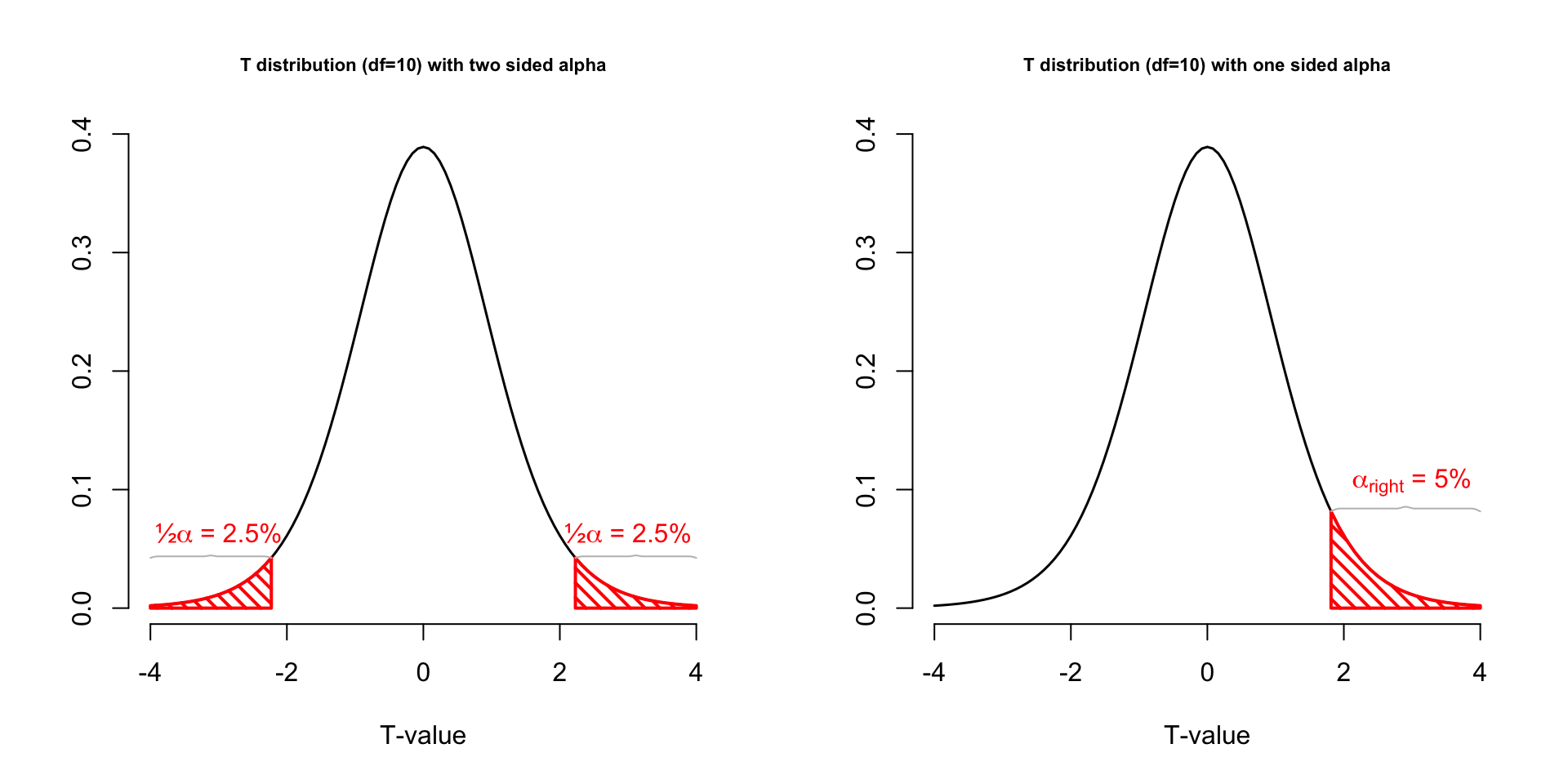
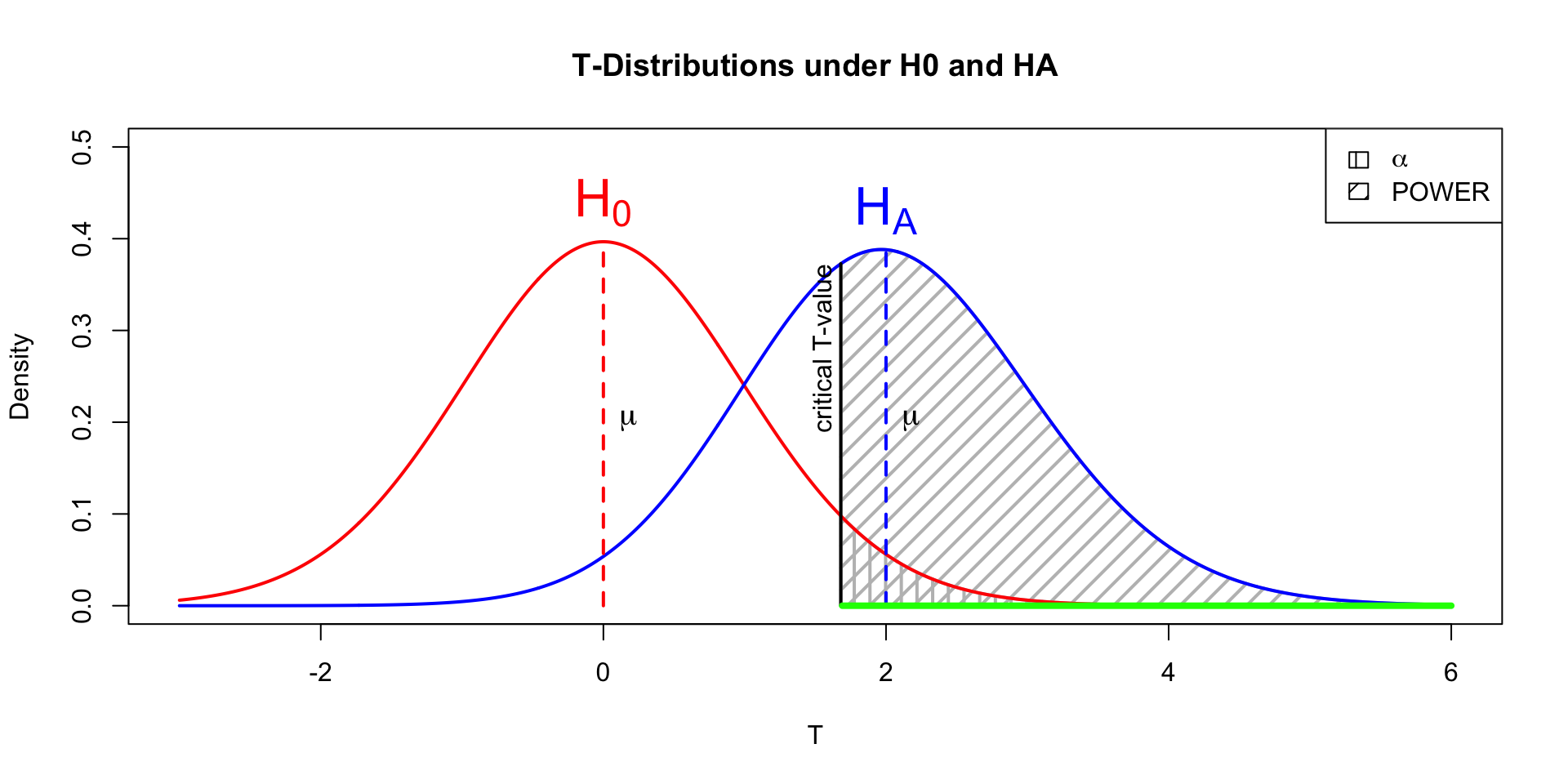
Power
- Strive for 80%
- Based on know effect size
- Calculate number of subjects needed
- Use G*Power to calculate

Alpha Power
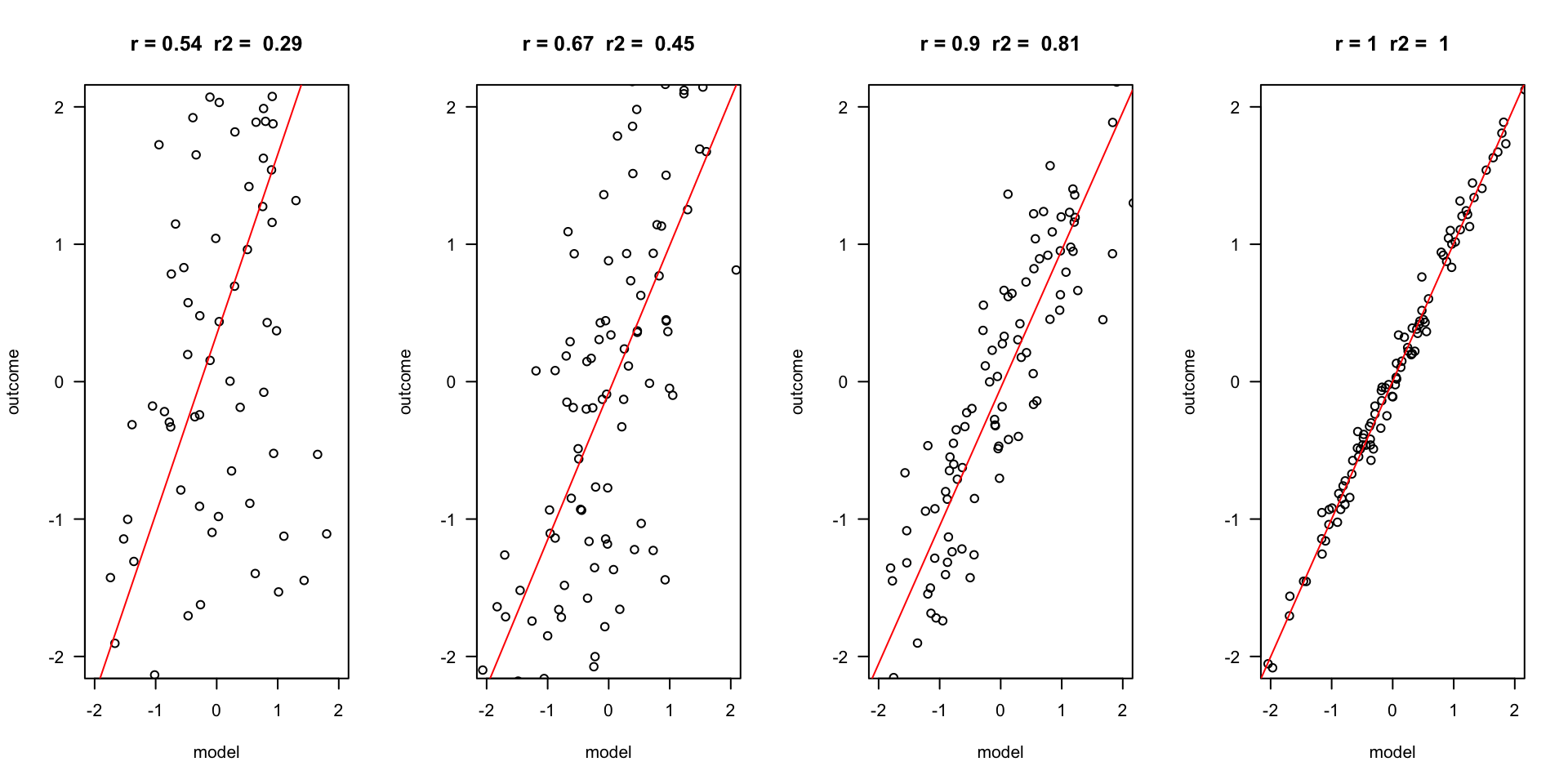
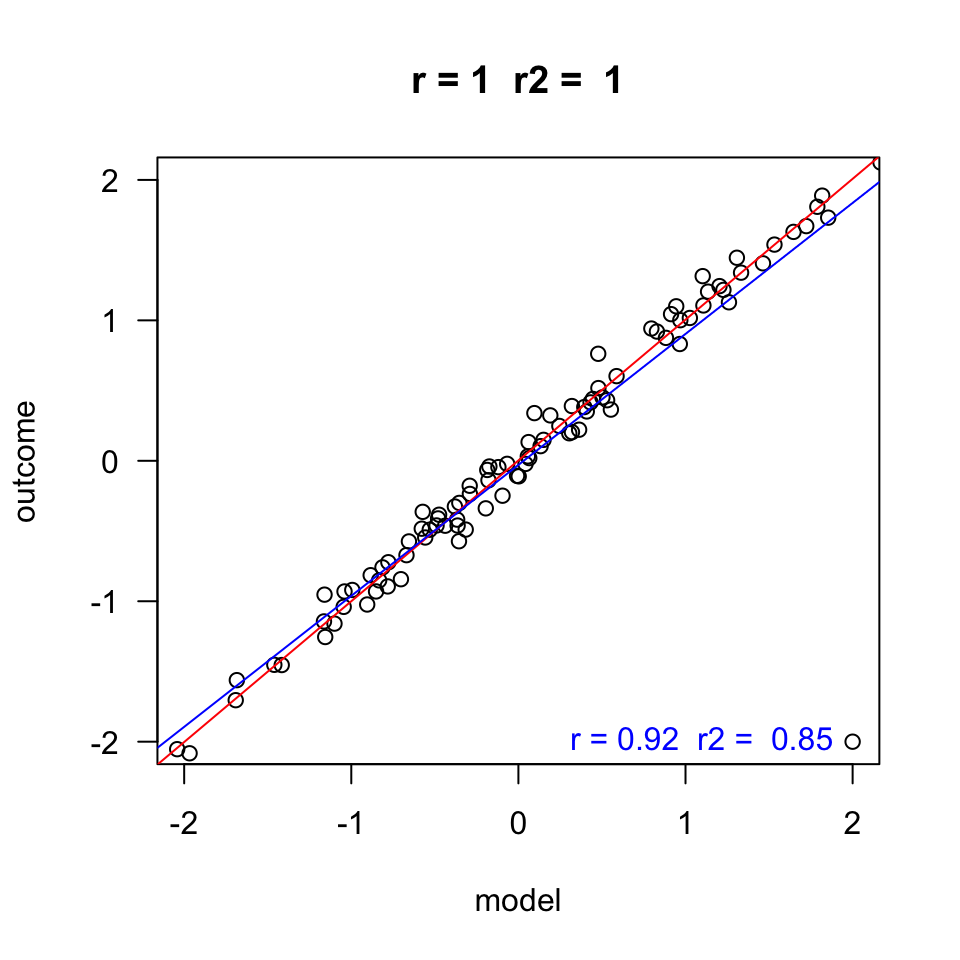
Outcome vs Model
Homoscedasticity
- Variance of residual should be equal across all expected values
- Look at scatterplot of standardized: expected values \(\times\) residuals. Roughly round shape is needed.
Code
set.seed(27364)
fit <- lm(x[2:n] ~ y[2:n])
ZPRED = scale(fit$fitted.values)
ZREDID = scale(fit$residuals)
plot(ZPRED, ZREDID)
abline(h = 0, v = 0, lwd=2)
#install.packages("plotrix")
if(!"plotrix" %in% installed.packages()) { install.packages("plotrix") };
library("plotrix")
draw.circle(0,0,1.7,col=rgb(1,0,0,.5))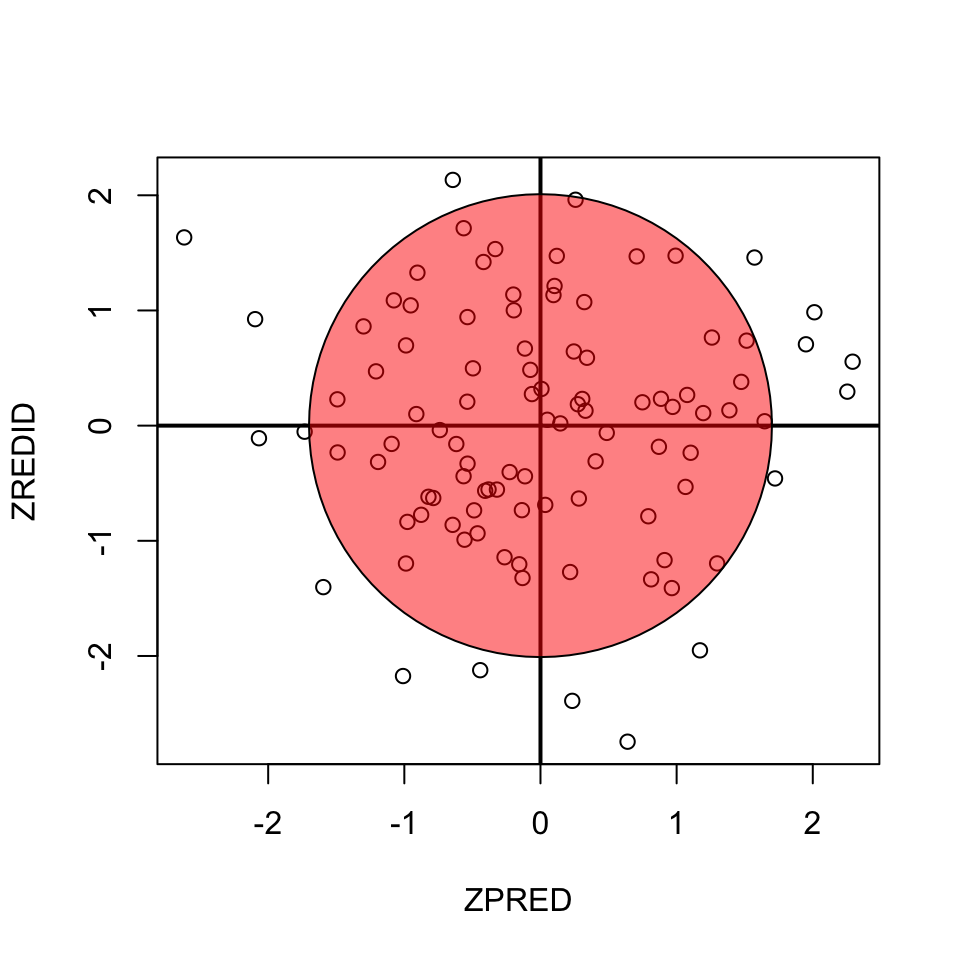
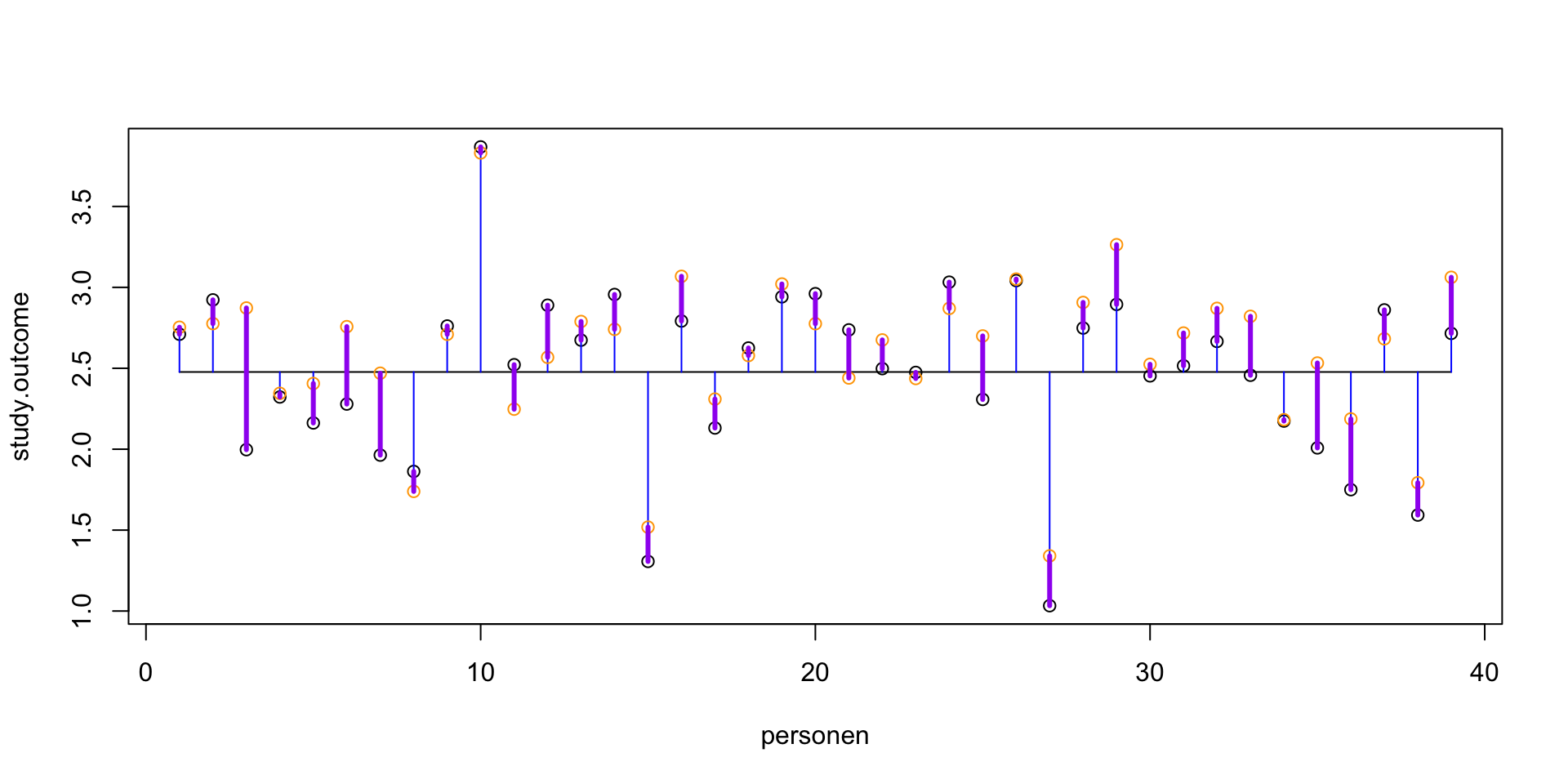
Multicollinearity
To adhere to the multicollinearity assumptien, there must not be a too high linear relation between the predictor variables.
This can be assessed through:
- Correlations
- Matrix scatterplot
- Tolerance > 0.2

Visual
Contact

![]()