William Sealy Gosset (aka Student) in 1908 (age 32)
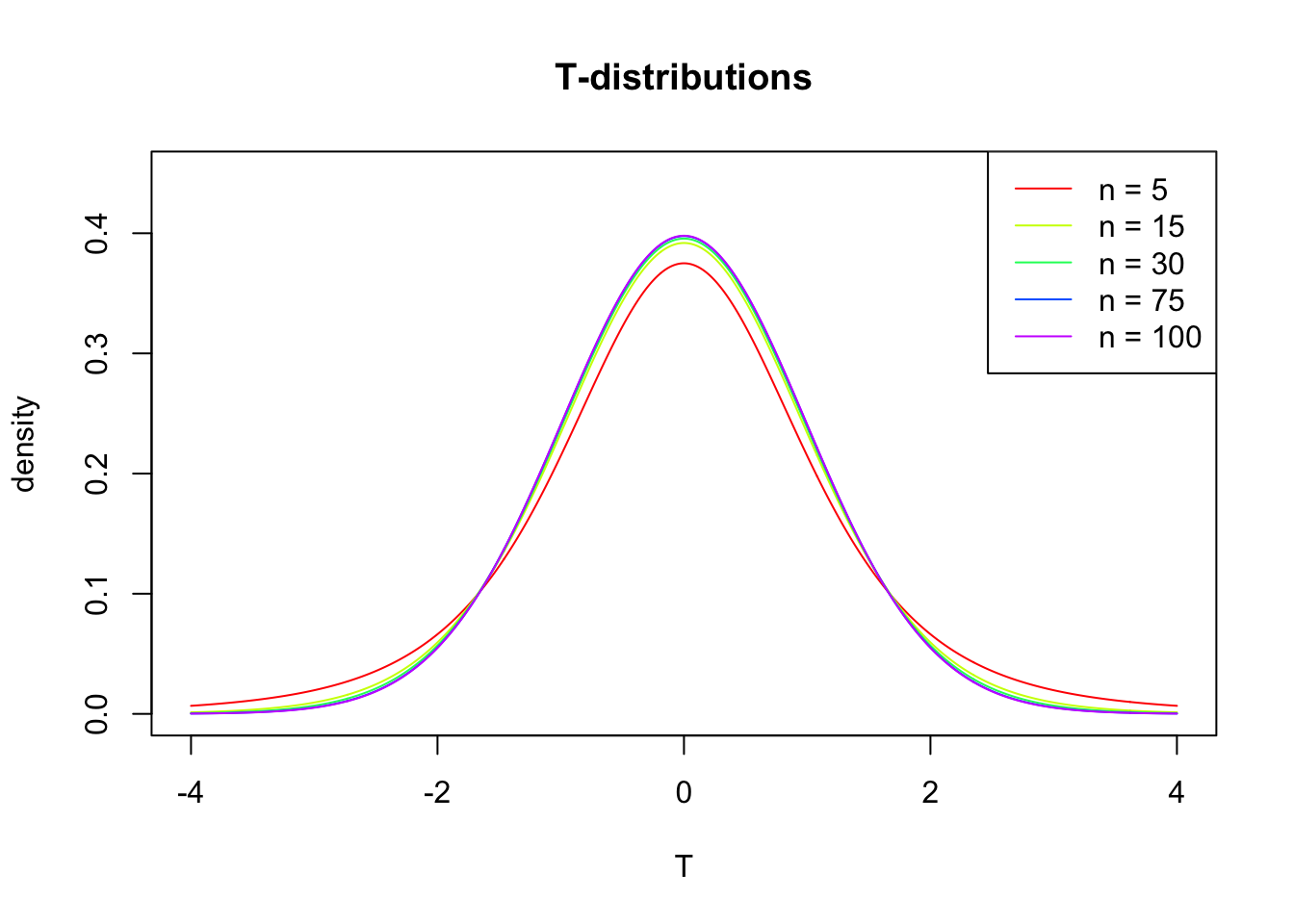
In probability and statistics, Student’s t-distribution (or simply the t-distribution) is any member of a family of continuous probability distributions that arises when estimating the mean of a normally distributed population in situations where the sample size is small and population standard deviation is unknown.
In the English-language literature it takes its name from William Sealy Gosset’s 1908 paper in Biometrika under the pseudonym “Student”. Gosset worked at the Guinness Brewery in Dublin, Ireland, and was interested in the problems of small samples, for example the chemical properties of barley where sample sizes might be as low as 3.
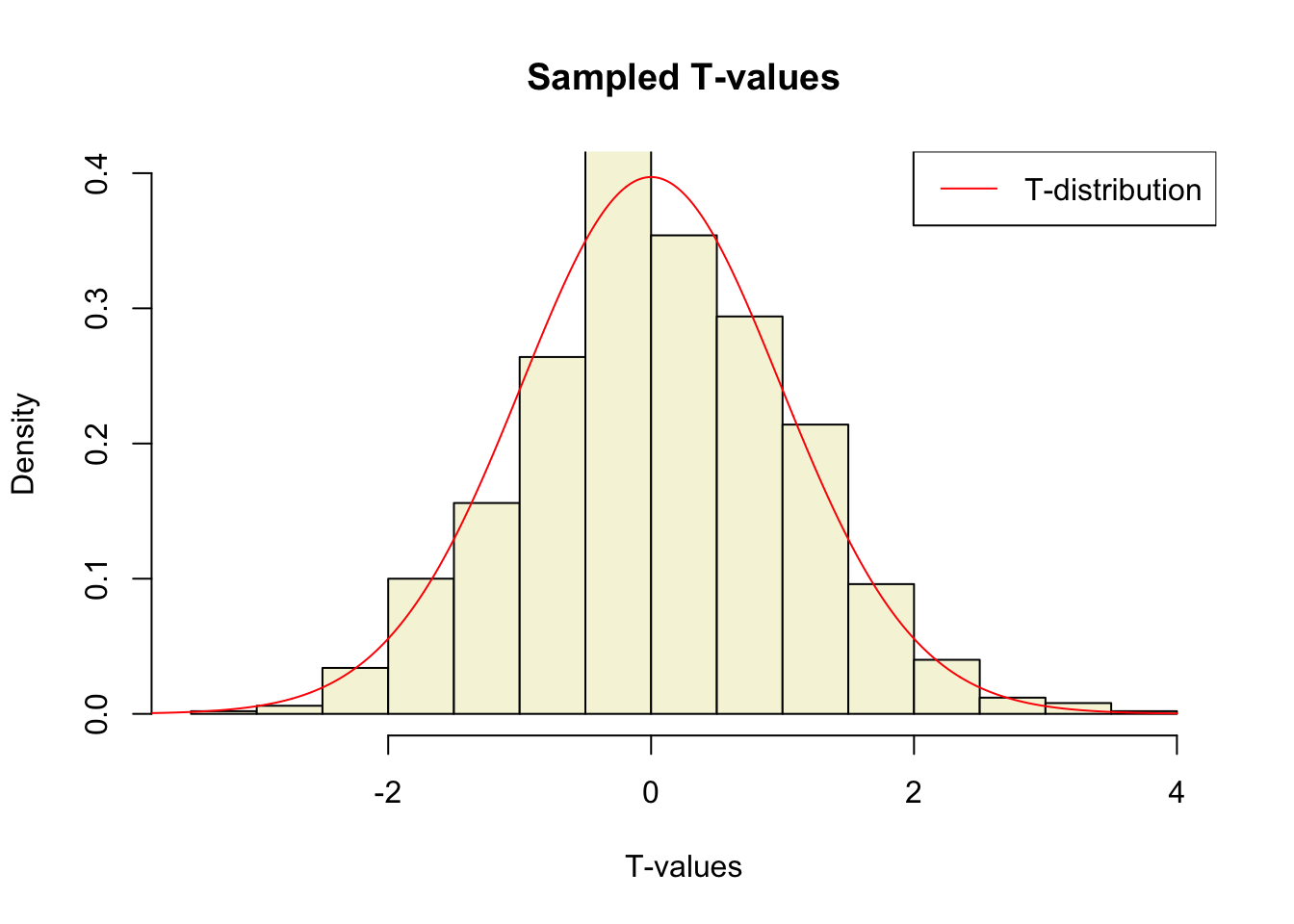
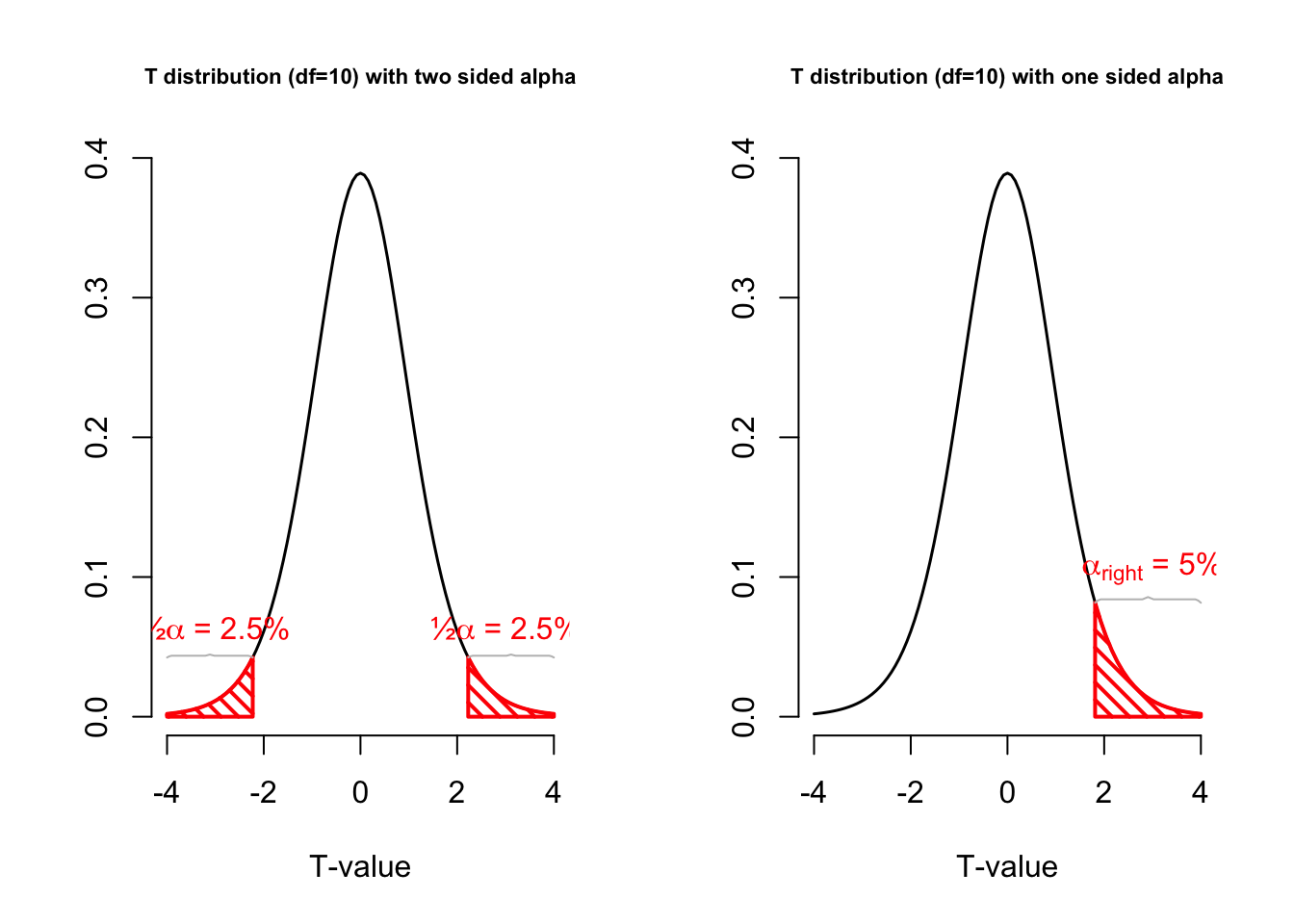
So the t-statistic represents the deviation of the sample mean \(\bar{x}\) from the population mean \(\mu\), considering the sample size, expressed as the degrees of freedom \(df = n - 1\)
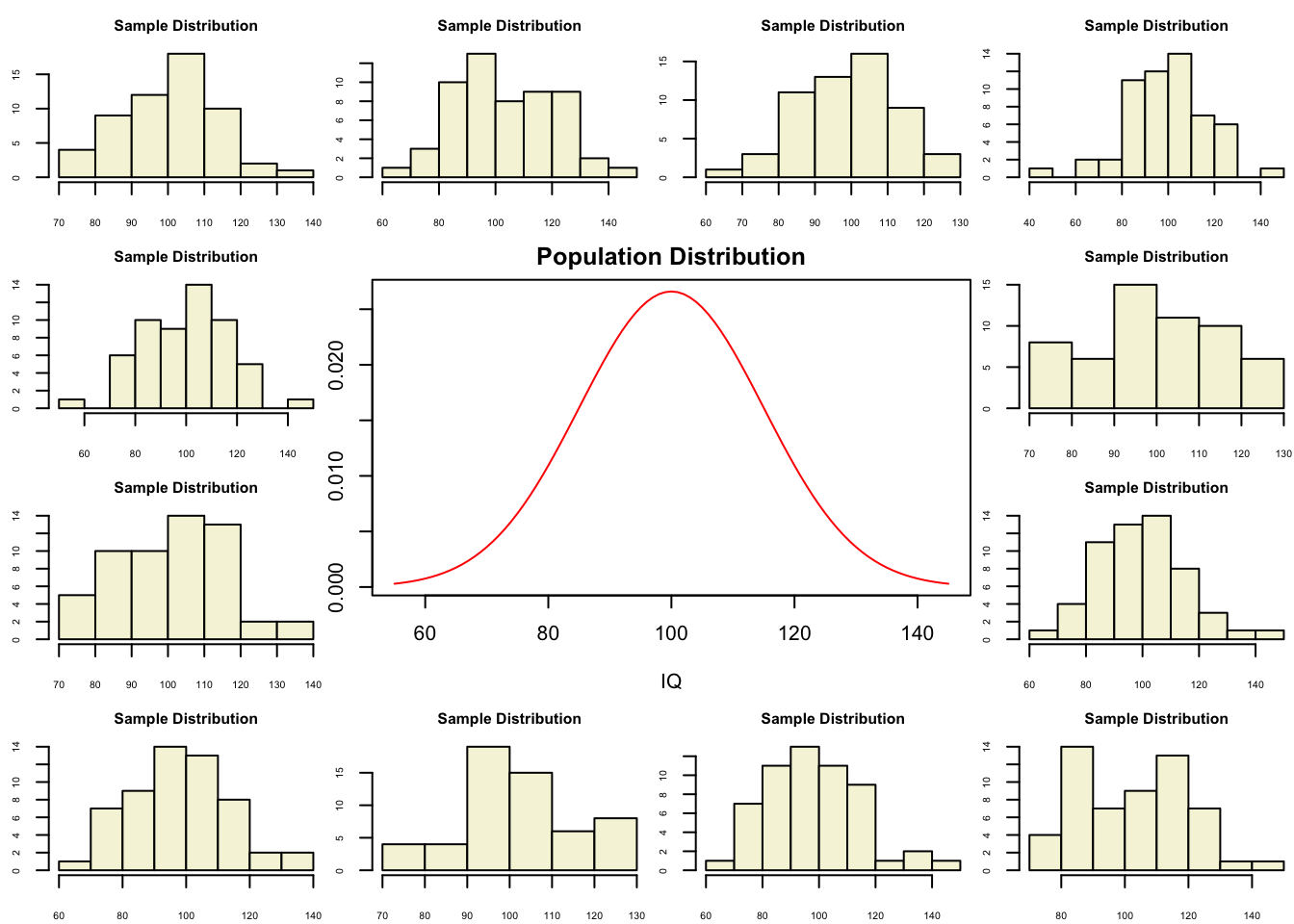
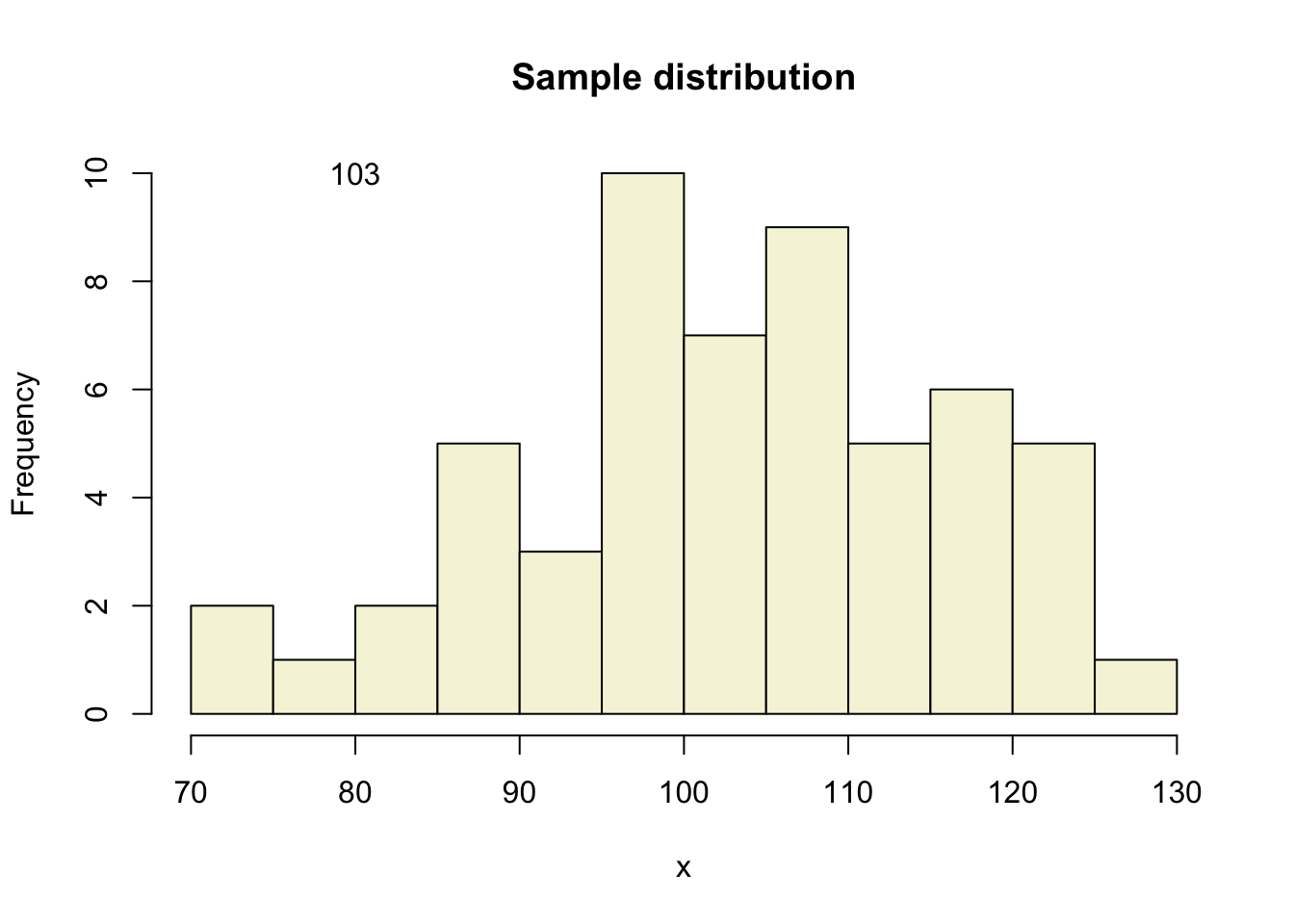
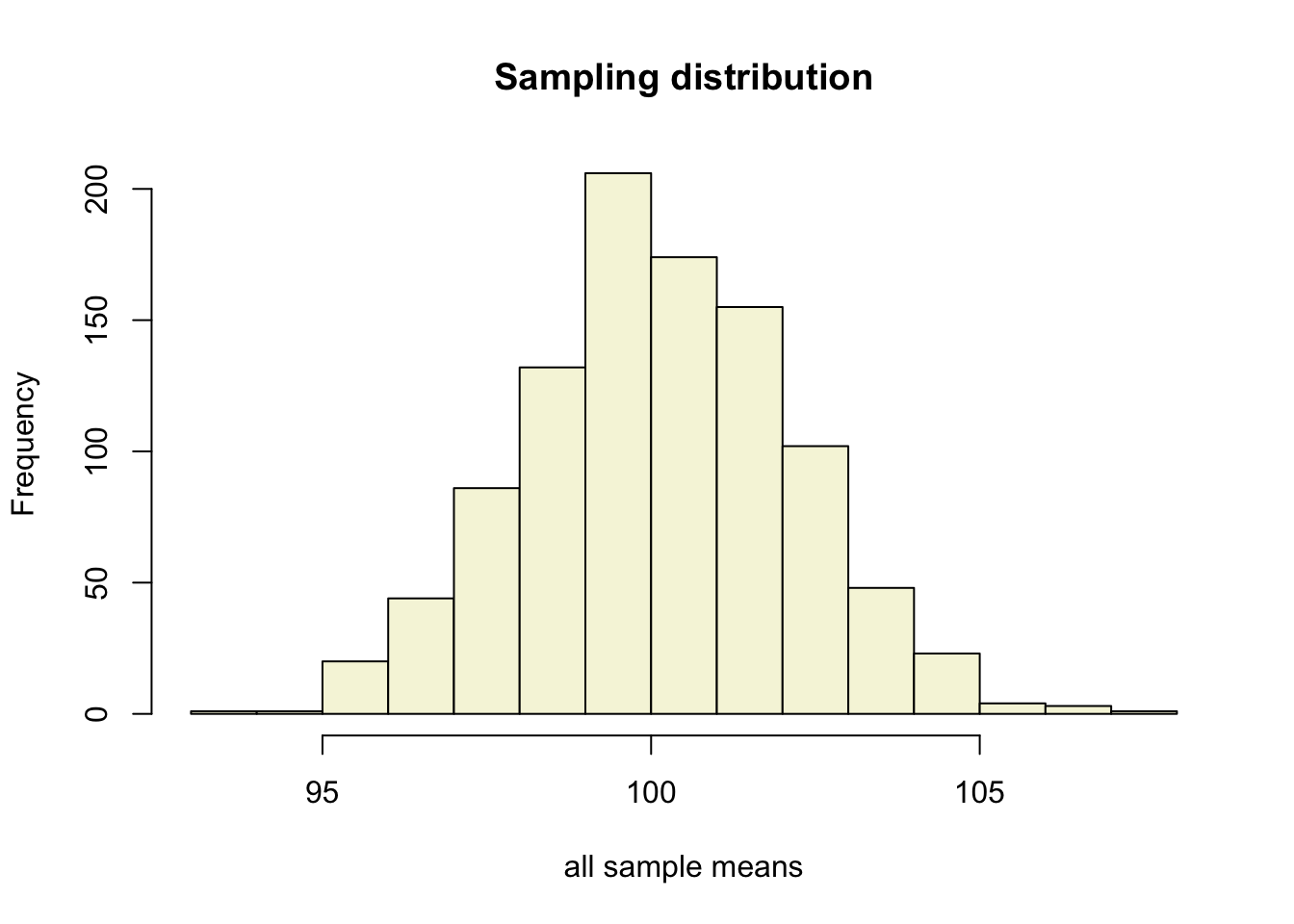
So if the population is normaly distributed (assumption of normality) the t-distribution represents the deviation of sample means from the population mean (\(\mu\)), given a certain sample size (\(df = n - 1\)).
The t-distibution therefore is different for different sample sizes and converges to a standard normal distribution if sample size is large enough.
In statistics, linear regression is a linear approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables denoted X.
In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters \(\beta\)’s are estimated from the data.
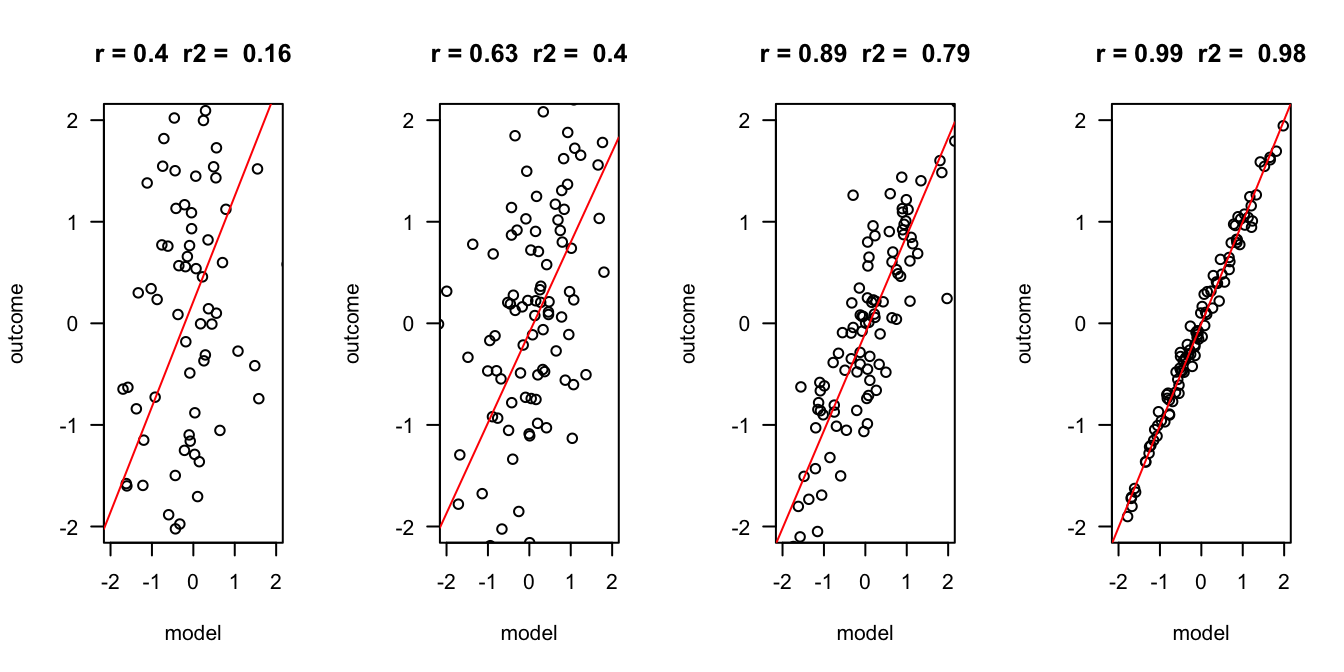
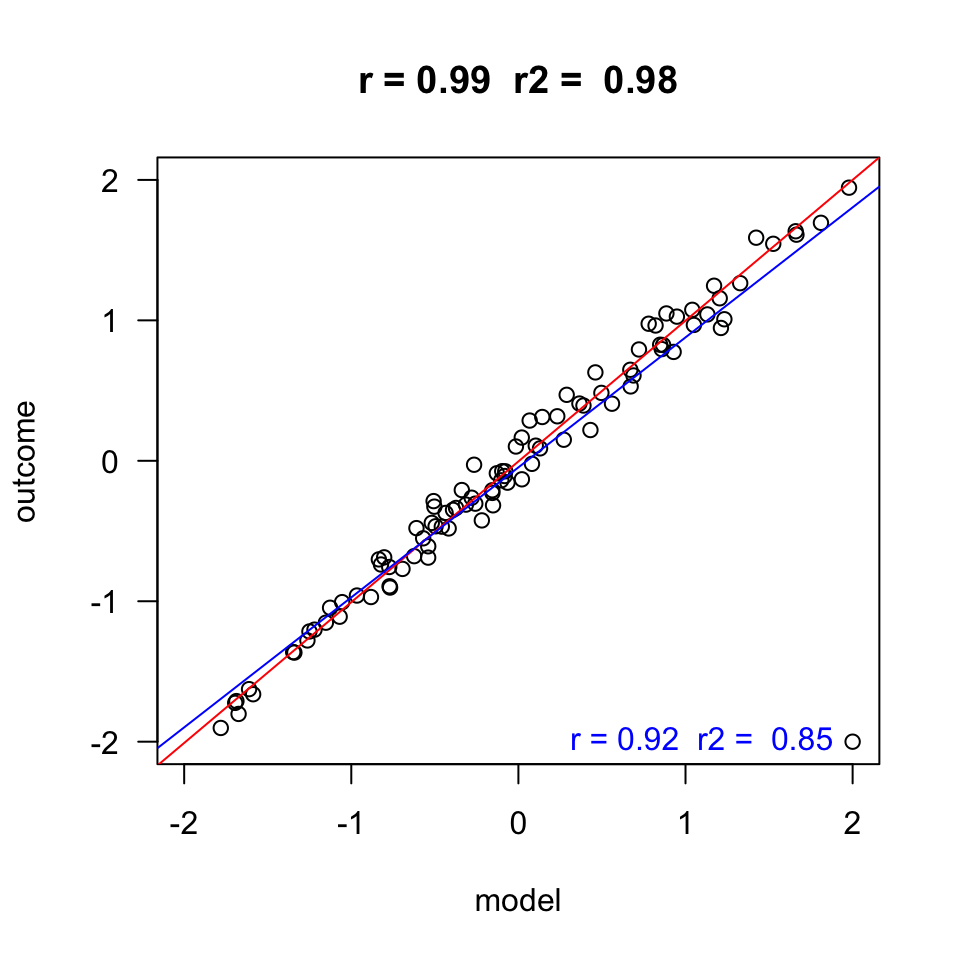
error =c(2, 1, .5, .1)n =100layout(matrix(1:4,1,4))for(e in error) { x =rnorm(n) y = x +rnorm(n, 0 , e) r =round(cor(x,y), 2) r.2=round(r^2, 2)plot(x,y, las =1, ylab ="outcome", xlab ="model", main =paste("r =", r," r2 = ", r.2), ylim=c(-2,2), xlim=c(-2,2)) fit <-lm(y ~ x)abline(fit, col ="red")}
Assumptions
A selection from Field (8.3.2.1. Assumptions of the linear model):
For simple regression
Sensitivity
Homoscedasticity
Plus multiple regressin
Multicollinearity
Linearity
Sensitivity
Outliers
Extreme residuals
Cook’s distance (< 1)
Mahalonobis (< 11 at N = 30)
Laverage (The average leverage value is defined as (k + 1)/n)
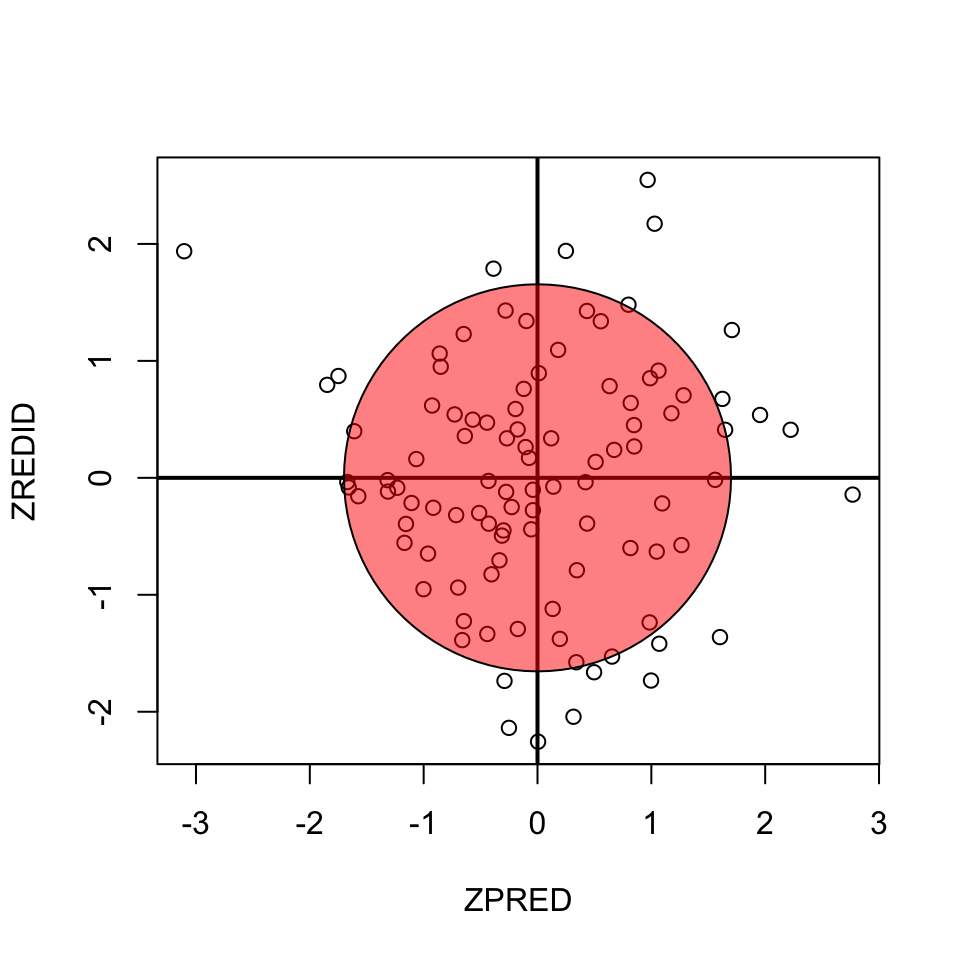
Homoscedasticity
Variance of residual should be equal across all expected values
Look at scatterplot of standardized: expected values \(\times\) residuals. Roughly round shape is needed.
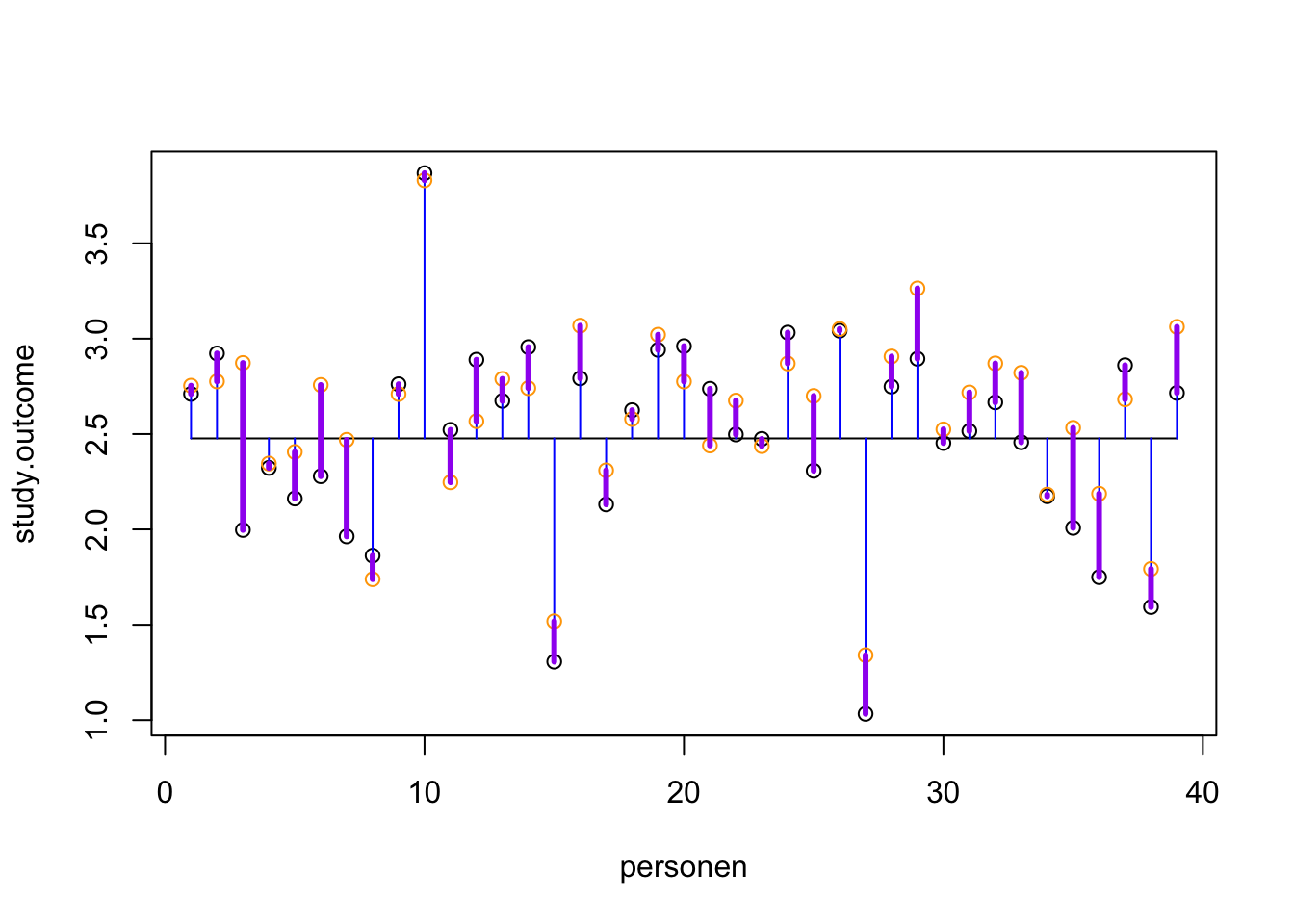
plot(study.outcome, xlab='personen', ylab='study.outcome')n =length(study.outcome)gemiddelde.study.outcome =mean(study.outcome)## Voeg het gemiddelde toelines(c(1, n), rep(gemiddelde.study.outcome, 2))## Wat is de totale variantie?segments(1:n, study.outcome, 1:n, gemiddelde.study.outcome, col='blue')## Wat zijn onze verwachte scores op basis van dit regressie model?points(model, col='orange')## Hoever zitten we ernaast, wat is de error?segments(1:n, study.outcome, 1:n, model, col='purple', lwd=3)
Explained variance
The explained variance is the deviation of the estimated model outcome compared to the total mean.
To get a percentage of explained variance, it must be compared to the total variance. In terms of squares: