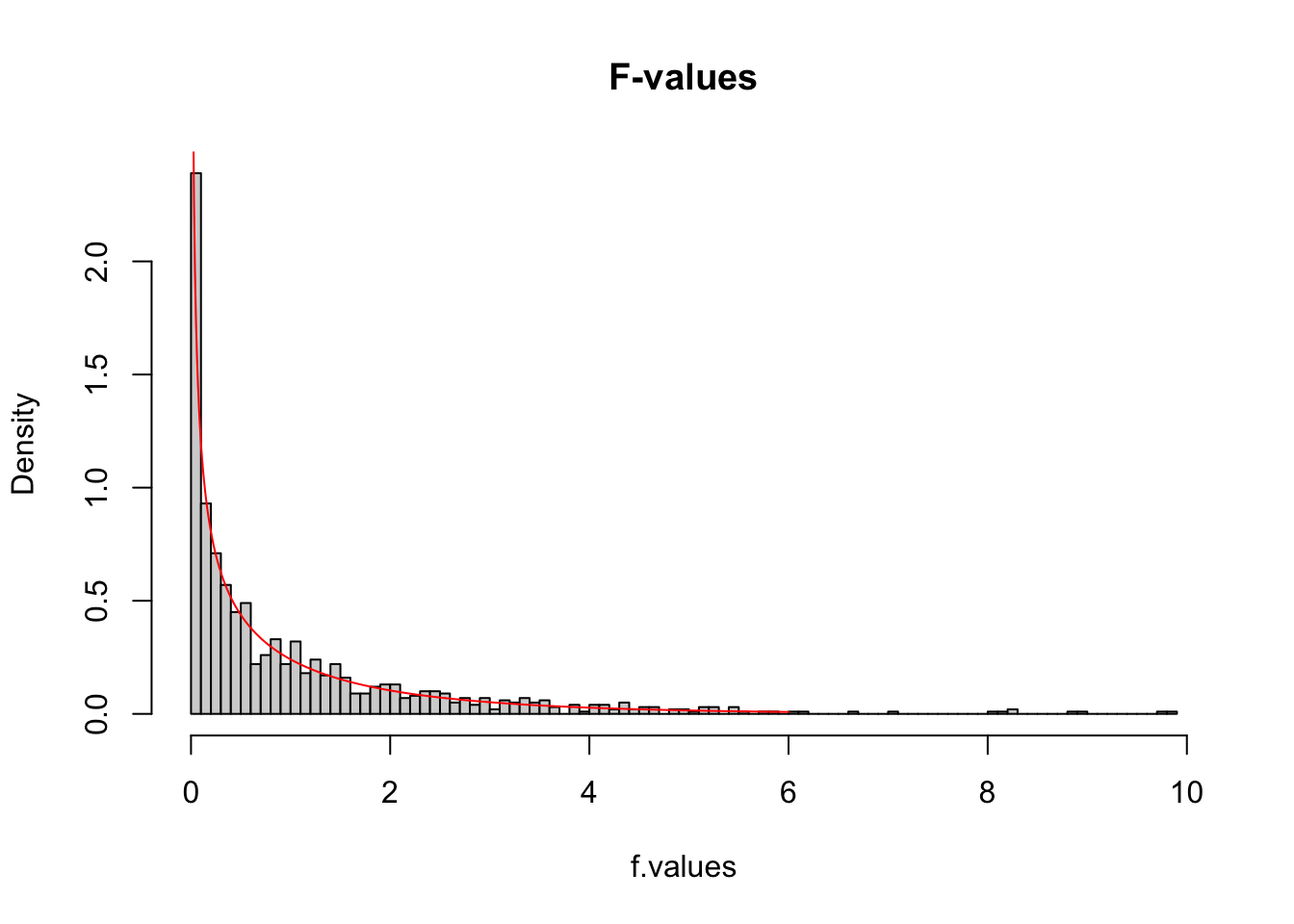
The F-distribution, also known as Snedecor’s F distribution or the Fisher–Snedecor distribution (after Ronald Fisher and George W. Snedecor) is, in probability theory and statistics, a continuous probability distribution. The F-distribution arises frequently as the null distribution of a test statistic, most notably in the analysis of variance; see F-test.
Sir Ronald Aylmer Fisher FRS (17 February 1890 – 29 July 1962), known as R.A. Fisher, was an English statistician, evolutionary biologist, mathematician, geneticist, and eugenicist. Fisher is known as one of the three principal founders of population genetics, creating a mathematical and statistical basis for biology and uniting natural selection with Mendelian genetics.
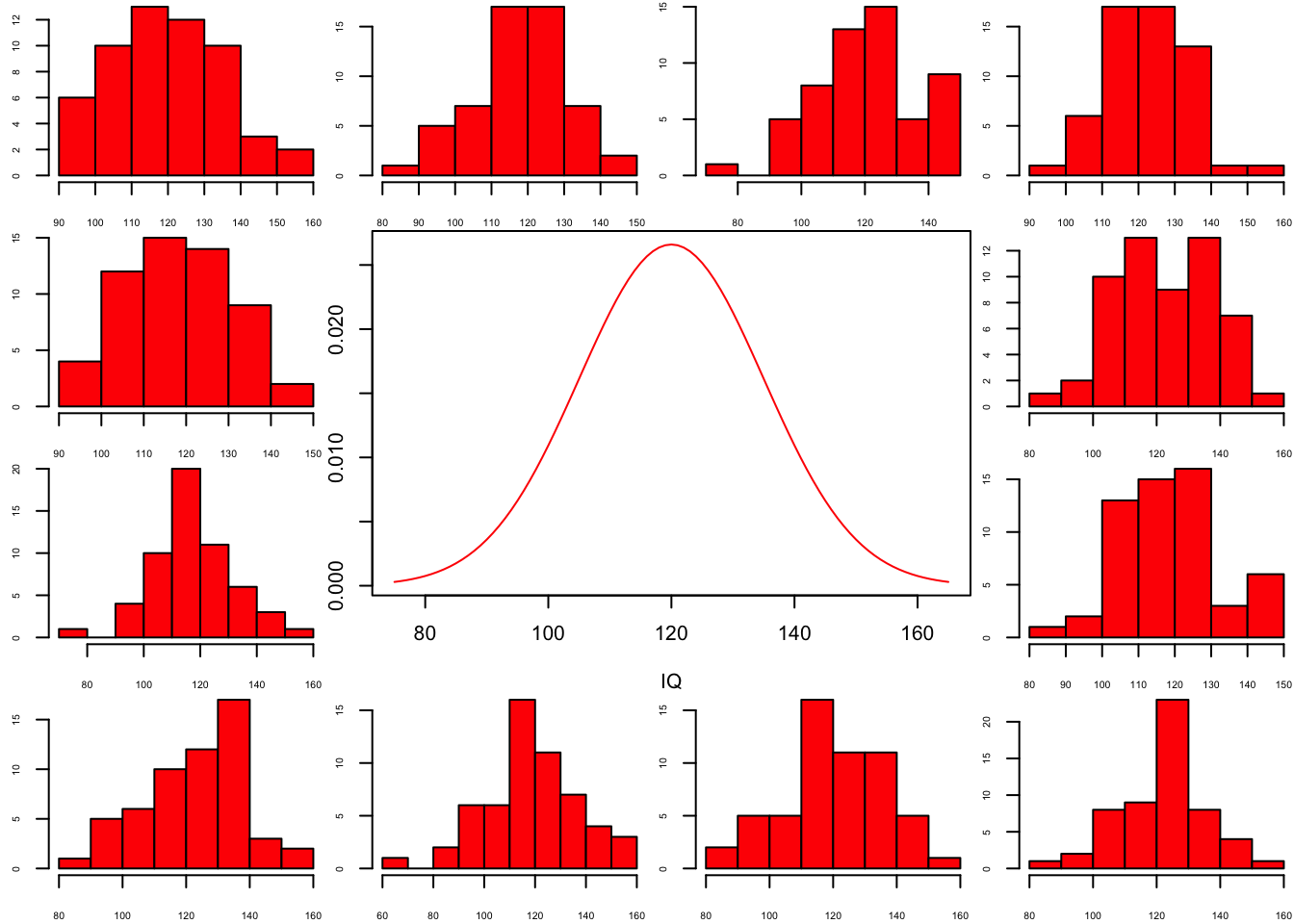
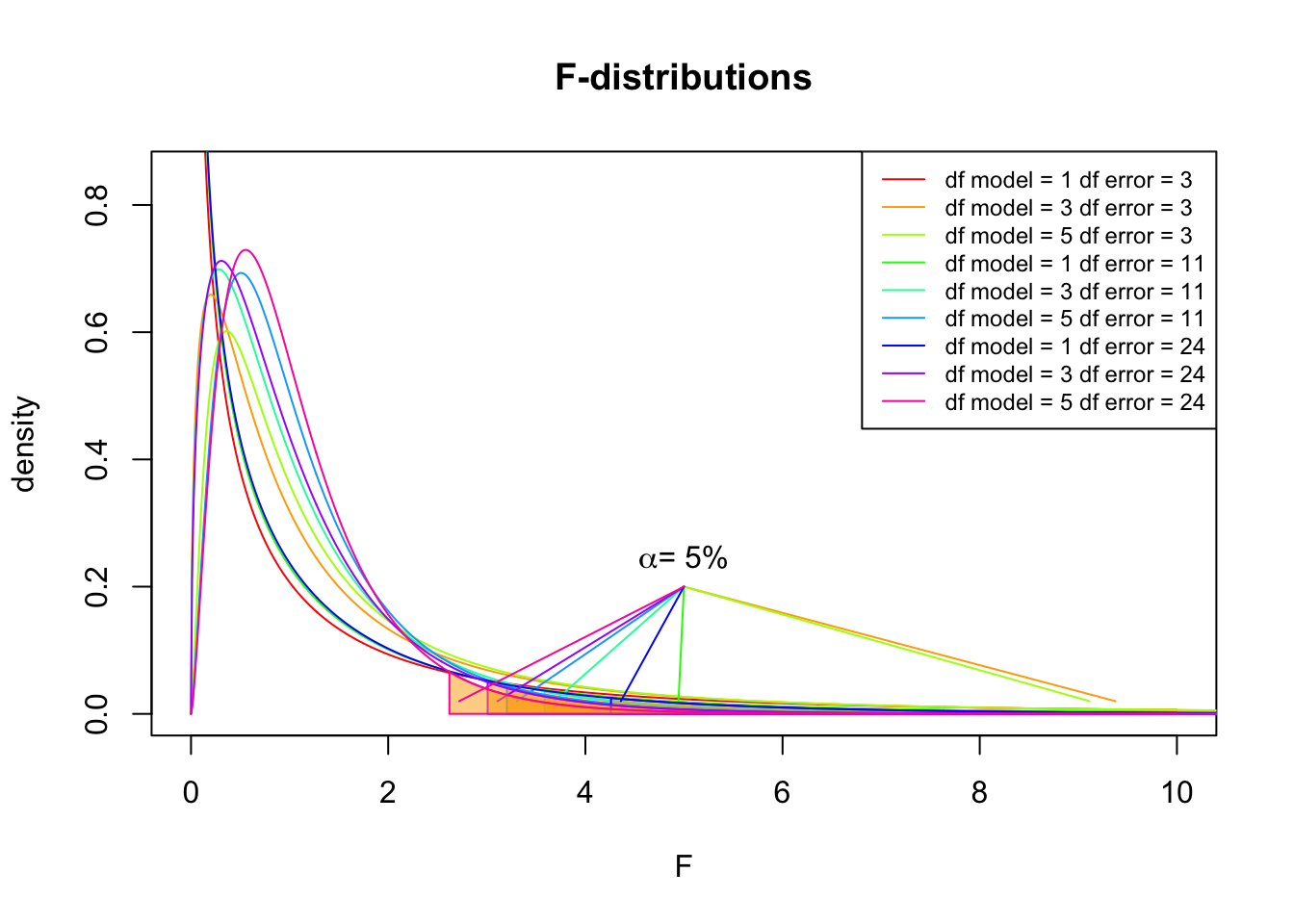
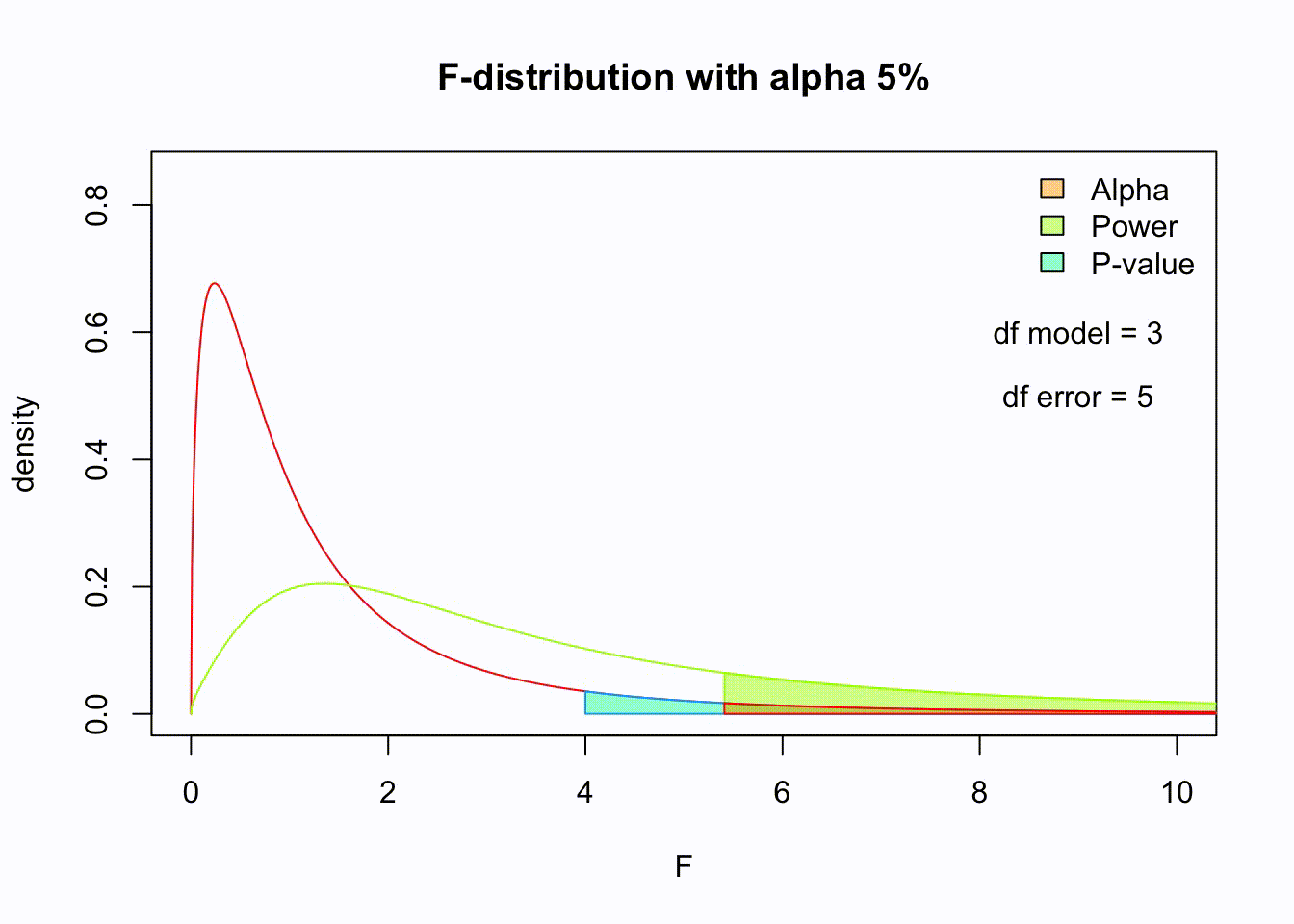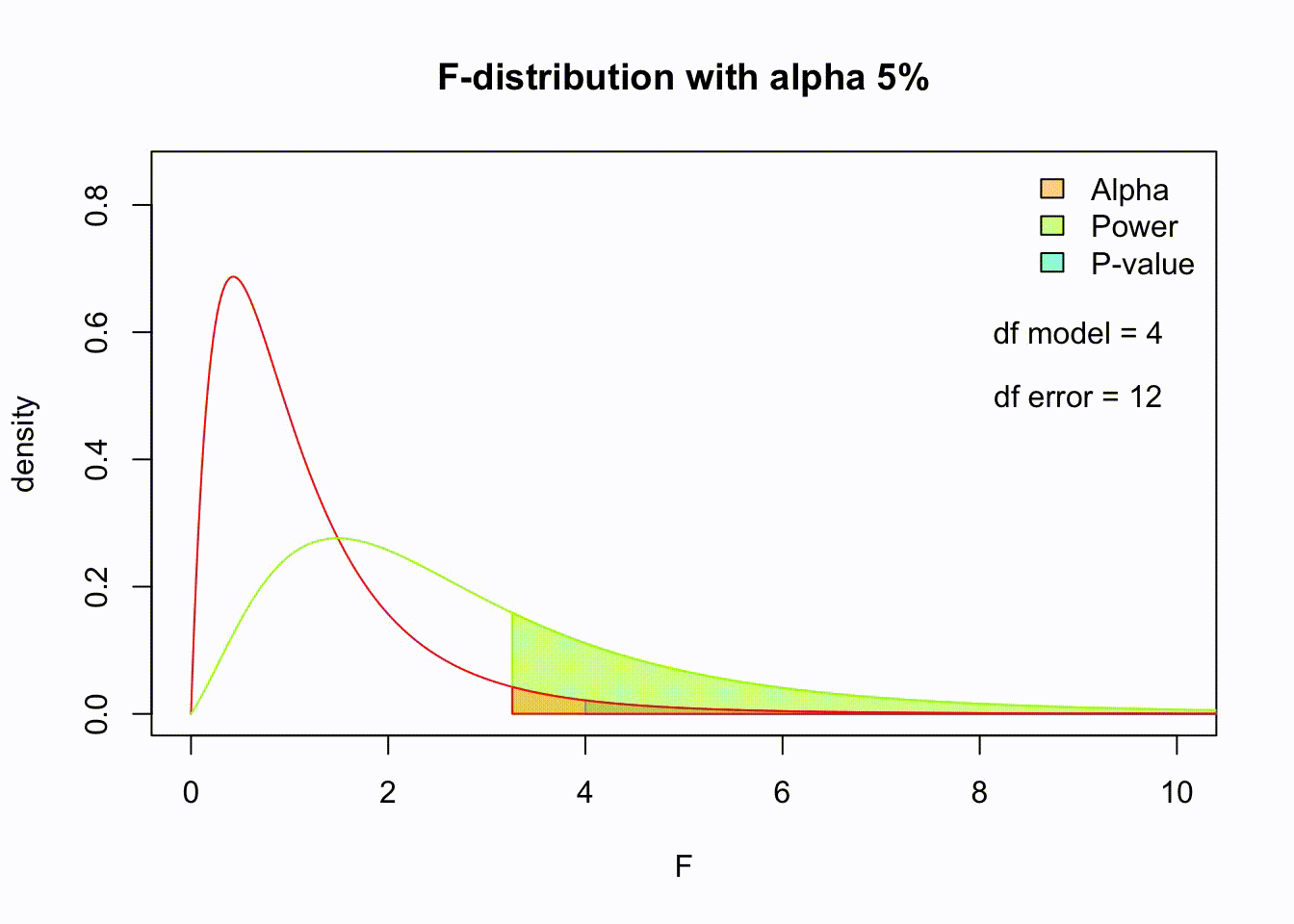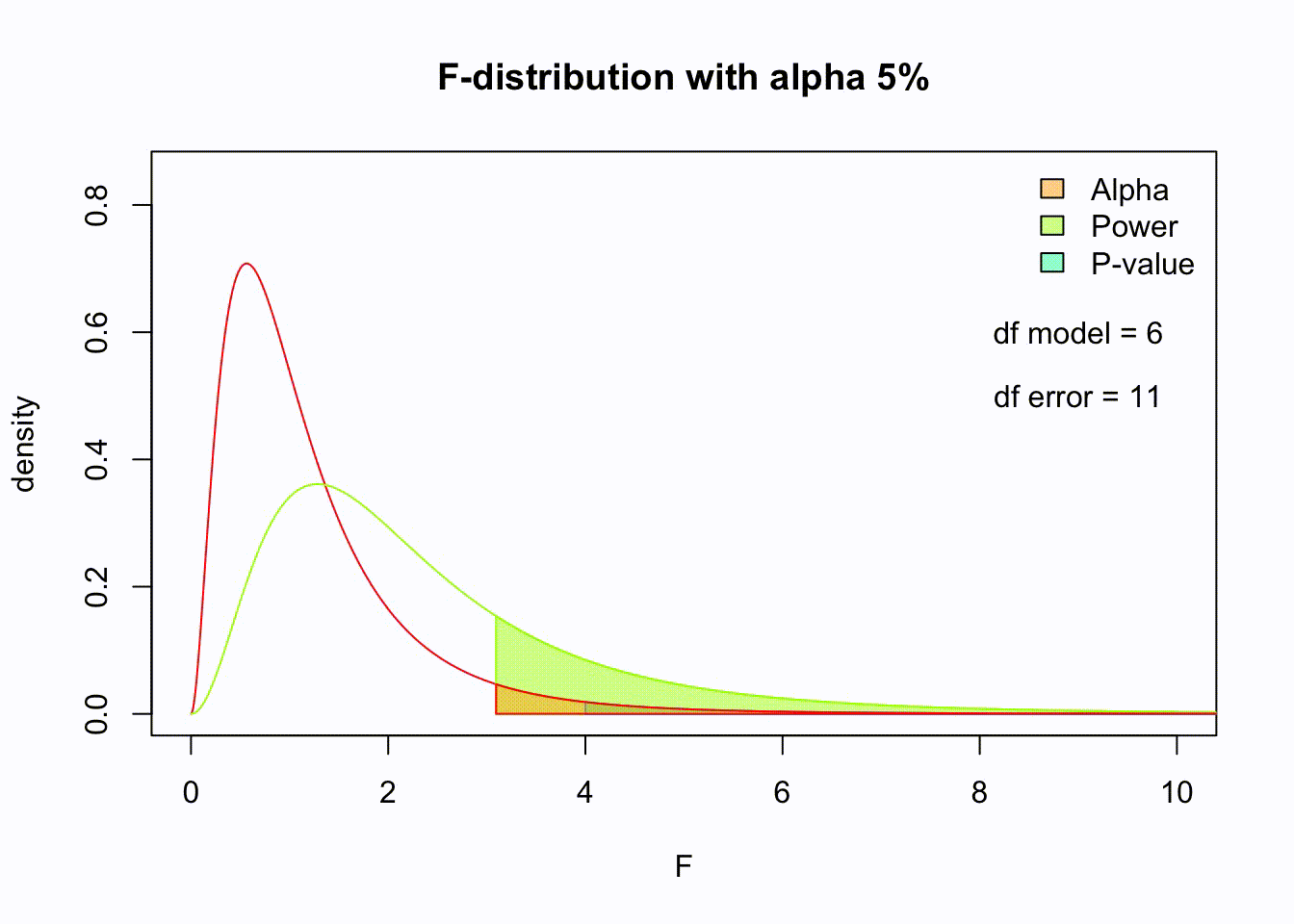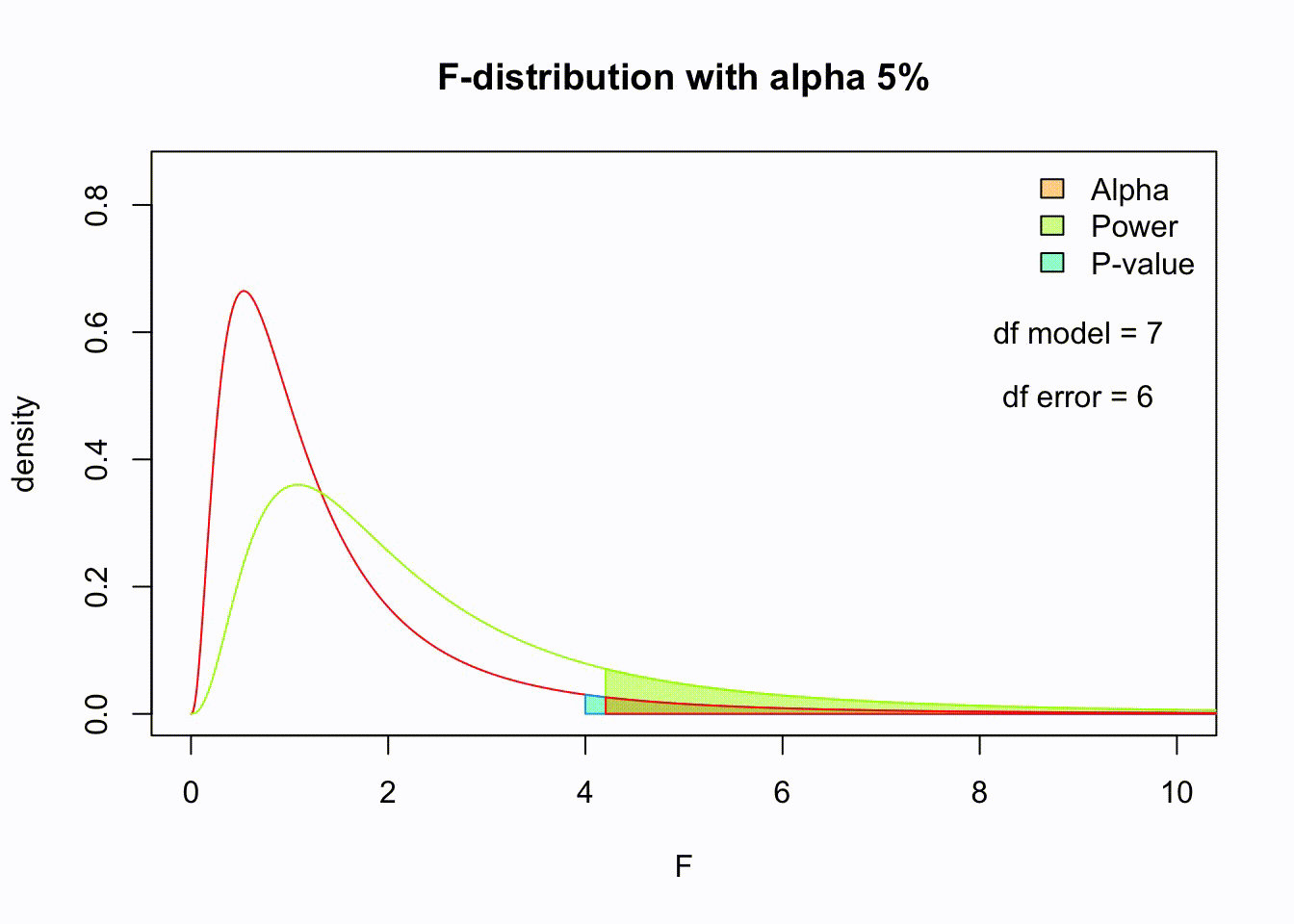
So if the population is normaly distributed (assumption of normality) the f-distribution represents the signal to noise ration given a certain number of samples (\({df}_{model} = k - 1\)) and sample size (\({df}_{error} = N - k\)).
The F-distibution therefore is different for different sample sizes and number of groups.
Hypothesis: \(H_0\) : equal population distributions (implies equal mean ranking) \(H_A\) : unequal mean ranking (two sided) \(H_A\) : higher mean ranking for one group.
Test statistic is difference between mean or sum of ranking.