Non-parametric tests
University of Amsterdam
7 oct 2022
Ranking
| rx | 1 | 2 | 3 | 4 | 5 | 6 |
| ry | 1 | 2 | 3 | 4 | 5 | 6 |
Wilcoxon rank-sum test

Developed by Frank Wilcoxon the rank-sum test is a nonparametric alternative to the independent samples t-test.
By first ranking \(x\) and then sum these ranks per group one would expect, under the null hypothesis, equal values for both groups.
After standardising this difference one can test using a standard normal distribution.
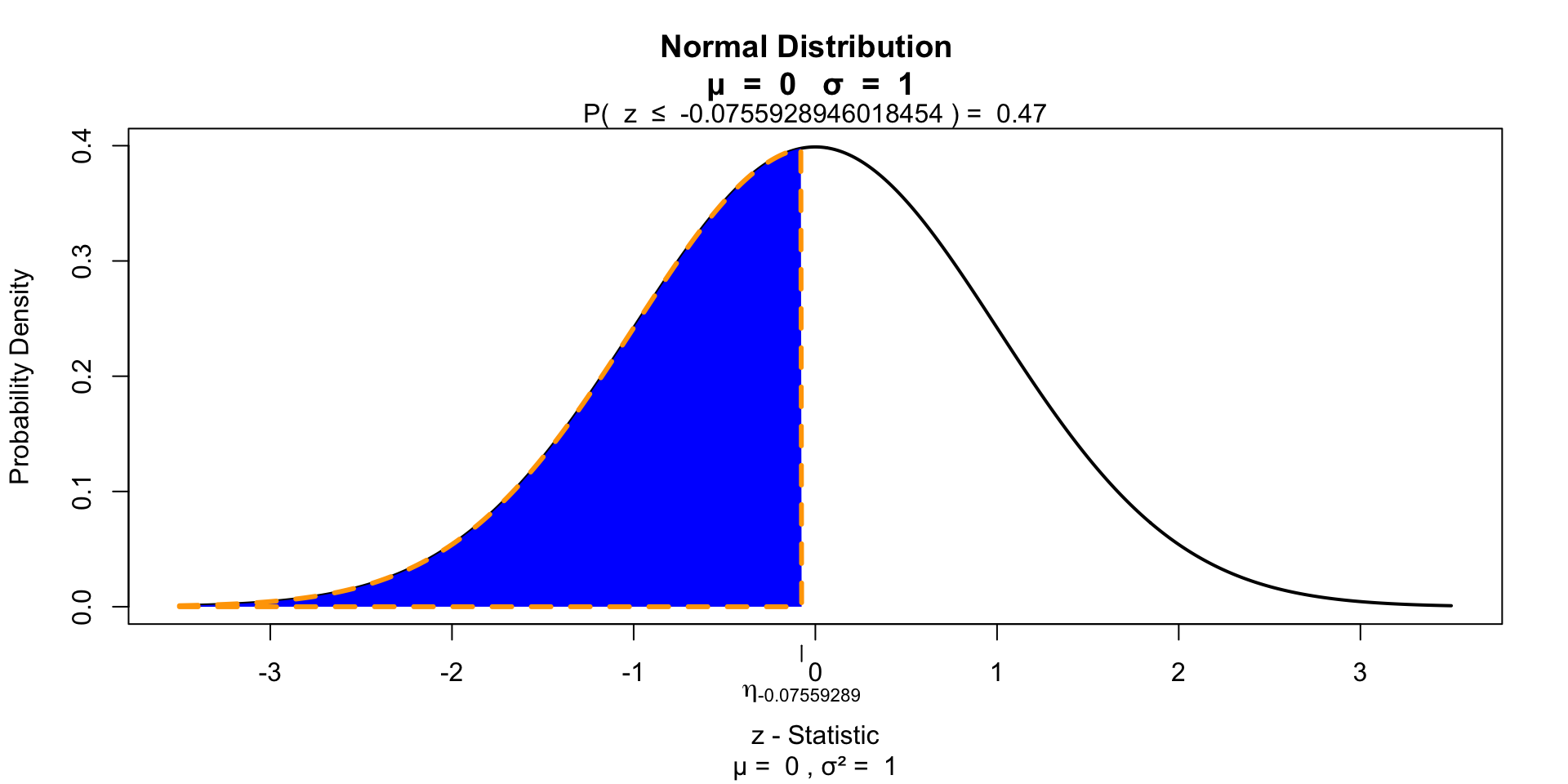
Test for significance 1 sided
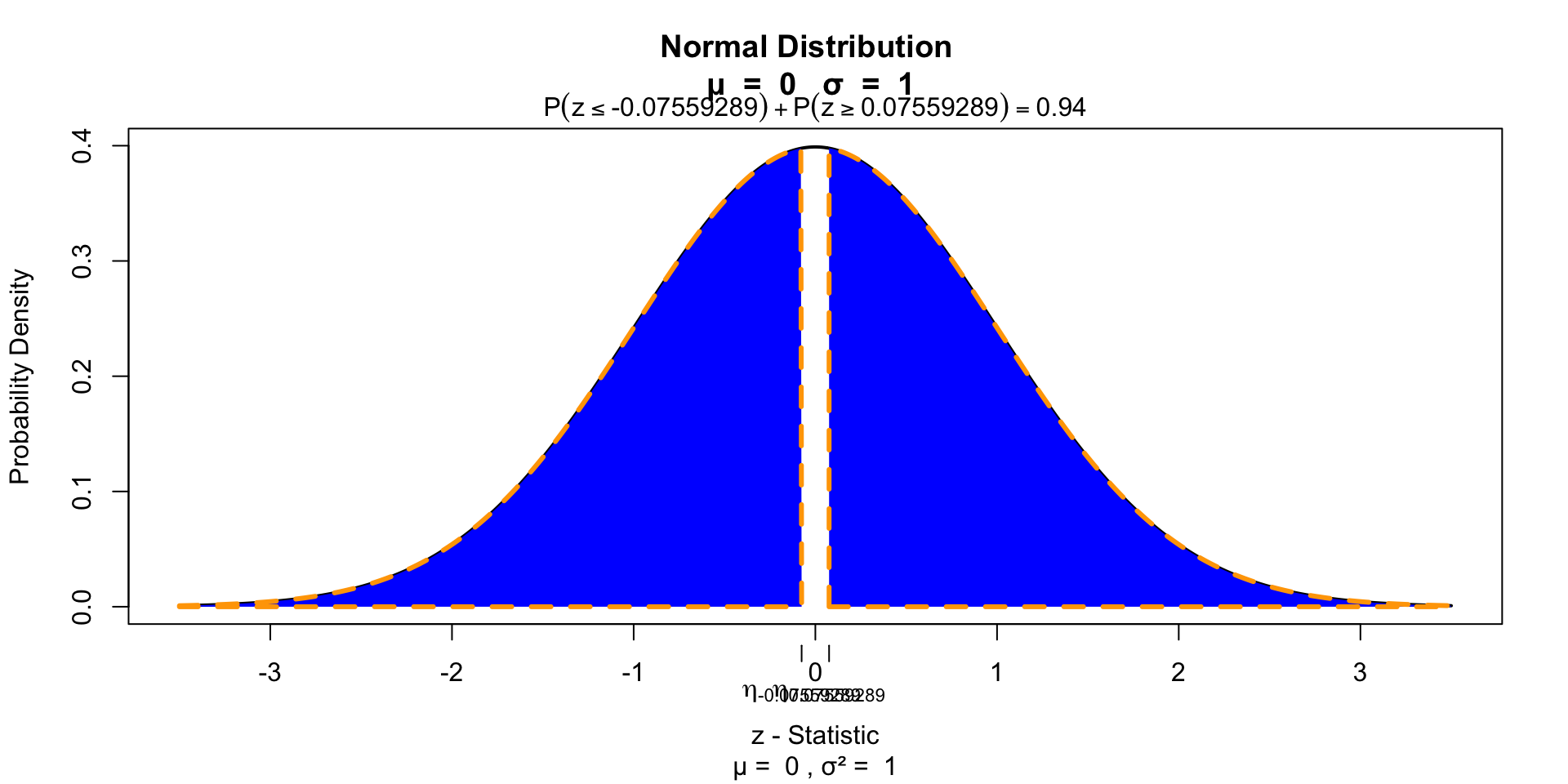
Test for significance 2 sided
Wilcoxon signed-rank test
The Wilcoxon signed-rank test is a nonparametric alternative to the paired samples t-test. It assigns + or - signs to the difference between two repeated measures. By ranking the differences and summing these ranks for the positive group, the null hypothesis is tested that both positive and negative differences are equal.
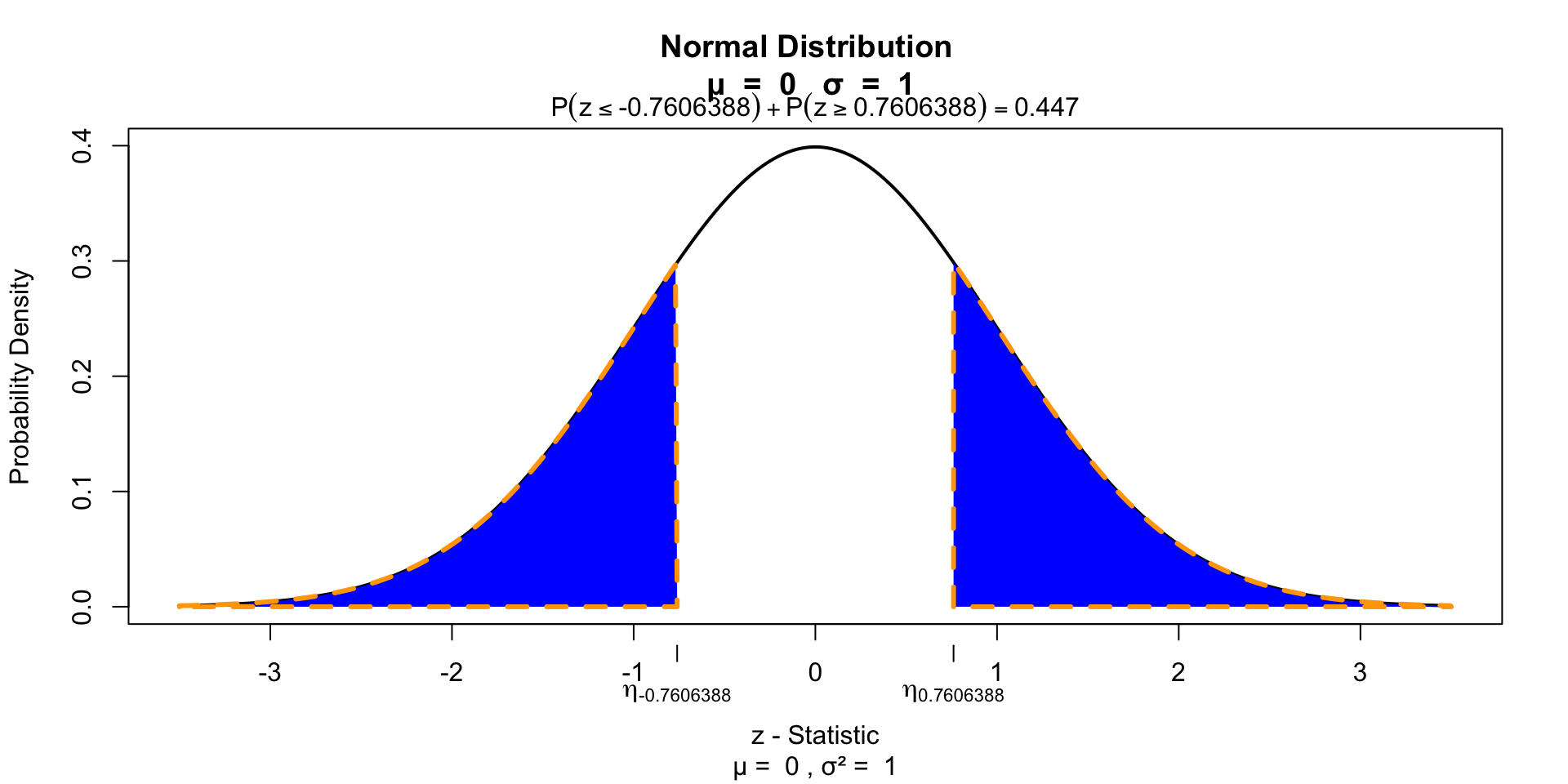
Test for significance
Kruskal–Wallis test

Created by William Henry Kruskal (L) and Wilson Allen Wallis (R), the Kruskal-Wallis test is a nonparametric alternative to the independent one-way ANOVA.
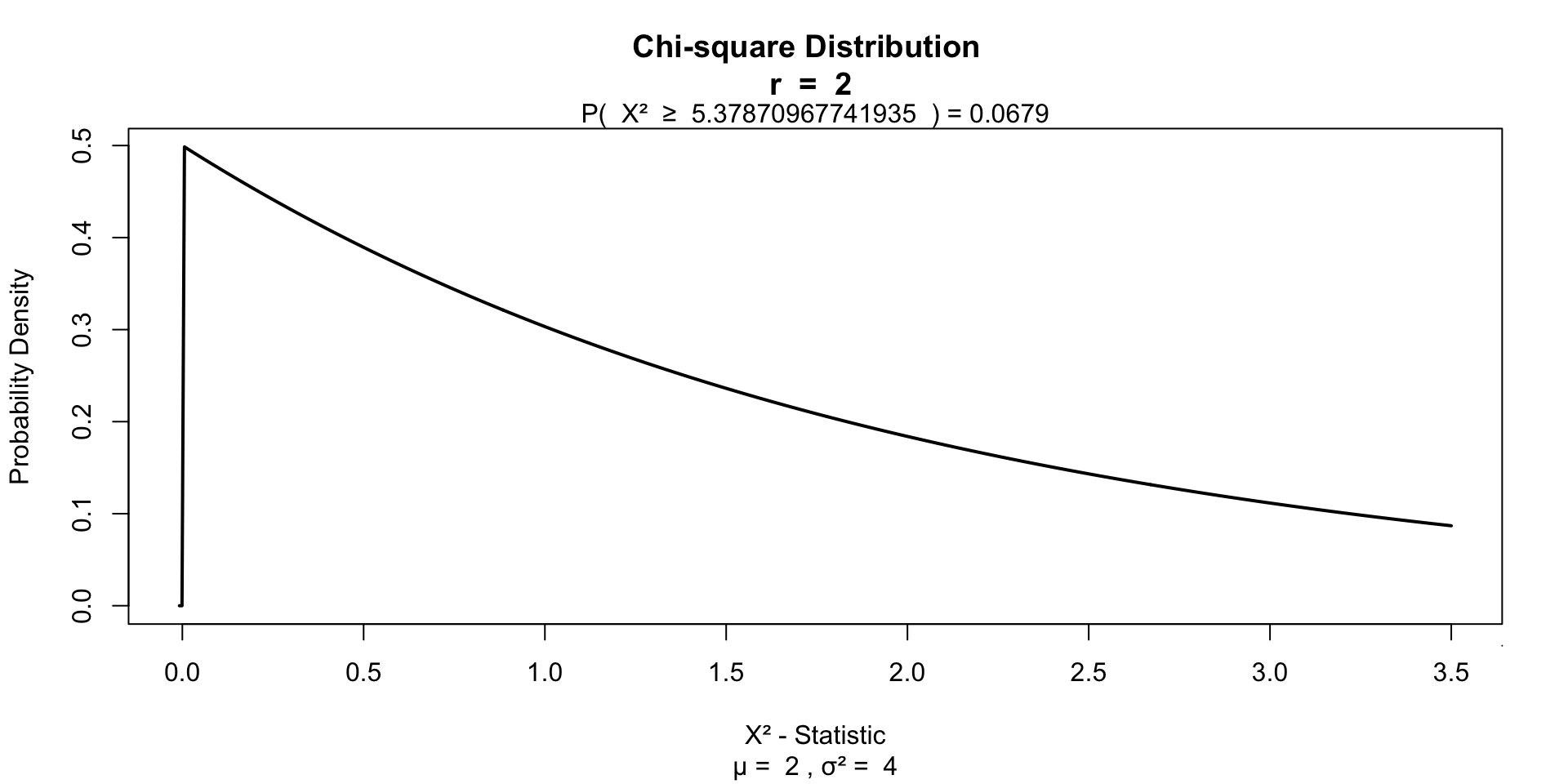
The Kruskal-Wallis test essentially subtracts the expected mean ranking from the calculated oberved mean ranking, which is \(\chi^2\) distributed.
Test for significance
Friedman’s ANOVA

Created by William Frederick Friedman the Friedman’s ANOVA is a nonparametric alternative to the repeated one-way ANOVA.
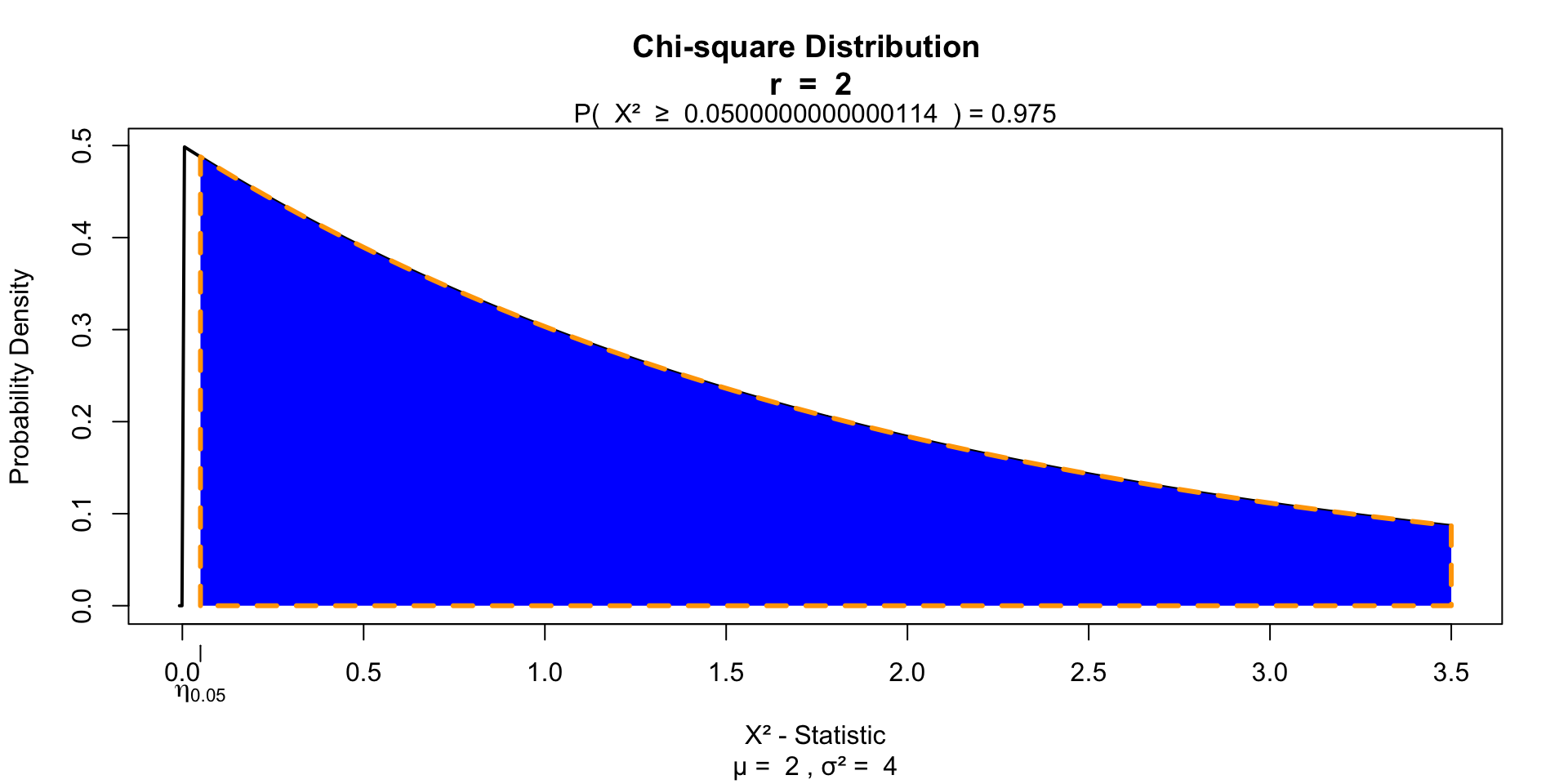
Just like the Kruskal-Wallis test, Friedman’s ANOVA, subtracts the expected mean ranking from the calculated observed mean ranking, which is also \(\chi^2\) distributed.
Test for significance
Contact

![]()