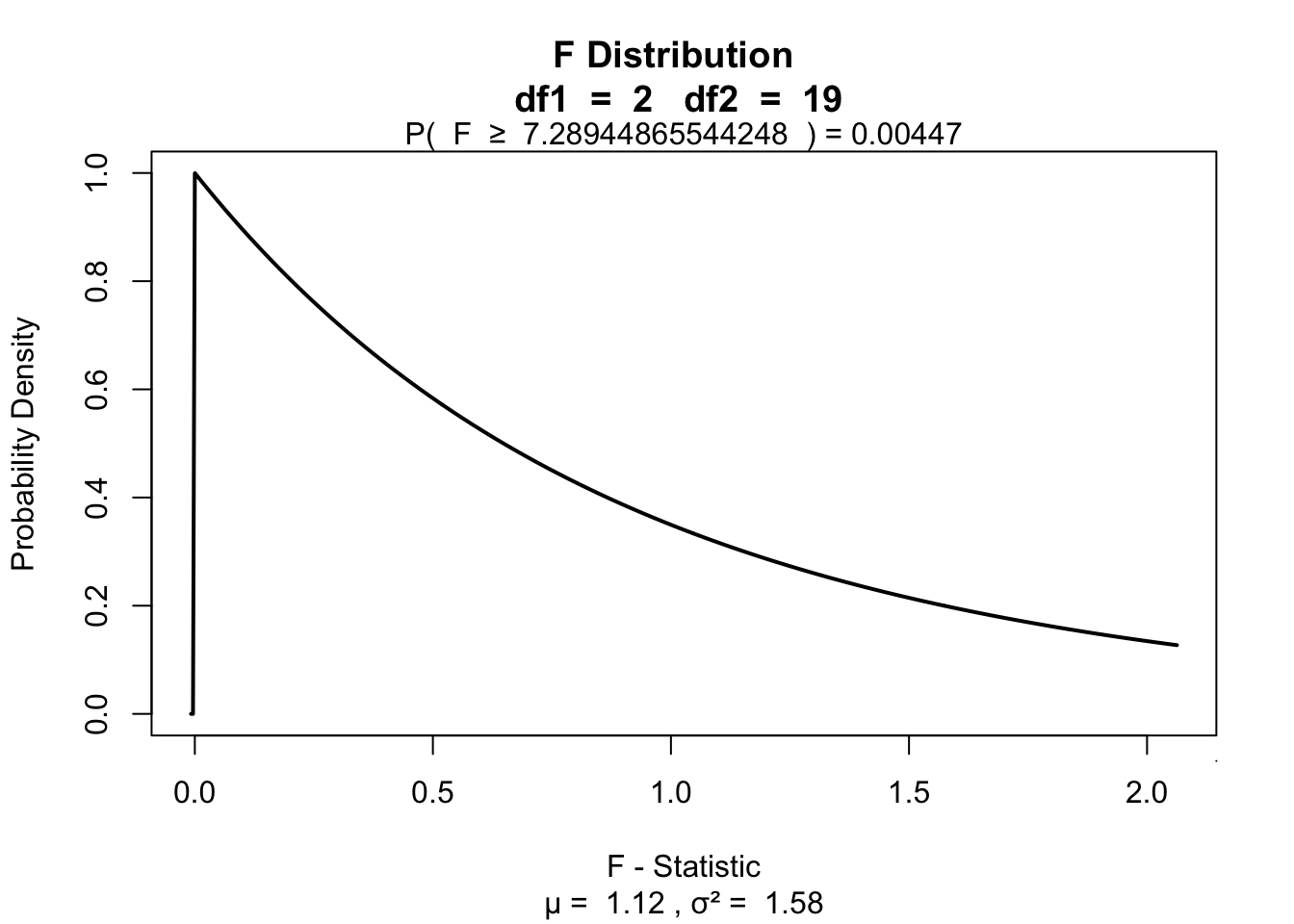
The F-distribution, also known as Snedecor’s F distribution or the Fisher–Snedecor distribution (after Ronald Fisher and George W. Snedecor) is, in probability theory and statistics, a continuous probability distribution. The F-distribution arises frequently as the null distribution of a test statistic, most notably in the analysis of variance; see F-test.
Sir Ronald Aylmer Fisher FRS (17 February 1890 – 29 July 1962), known as R.A. Fisher, was an English statistician, evolutionary biologist, mathematician, geneticist, and eugenicist. Fisher is known as one of the three principal founders of population genetics, creating a mathematical and statistical basis for biology and uniting natural selection with Mendelian genetics.
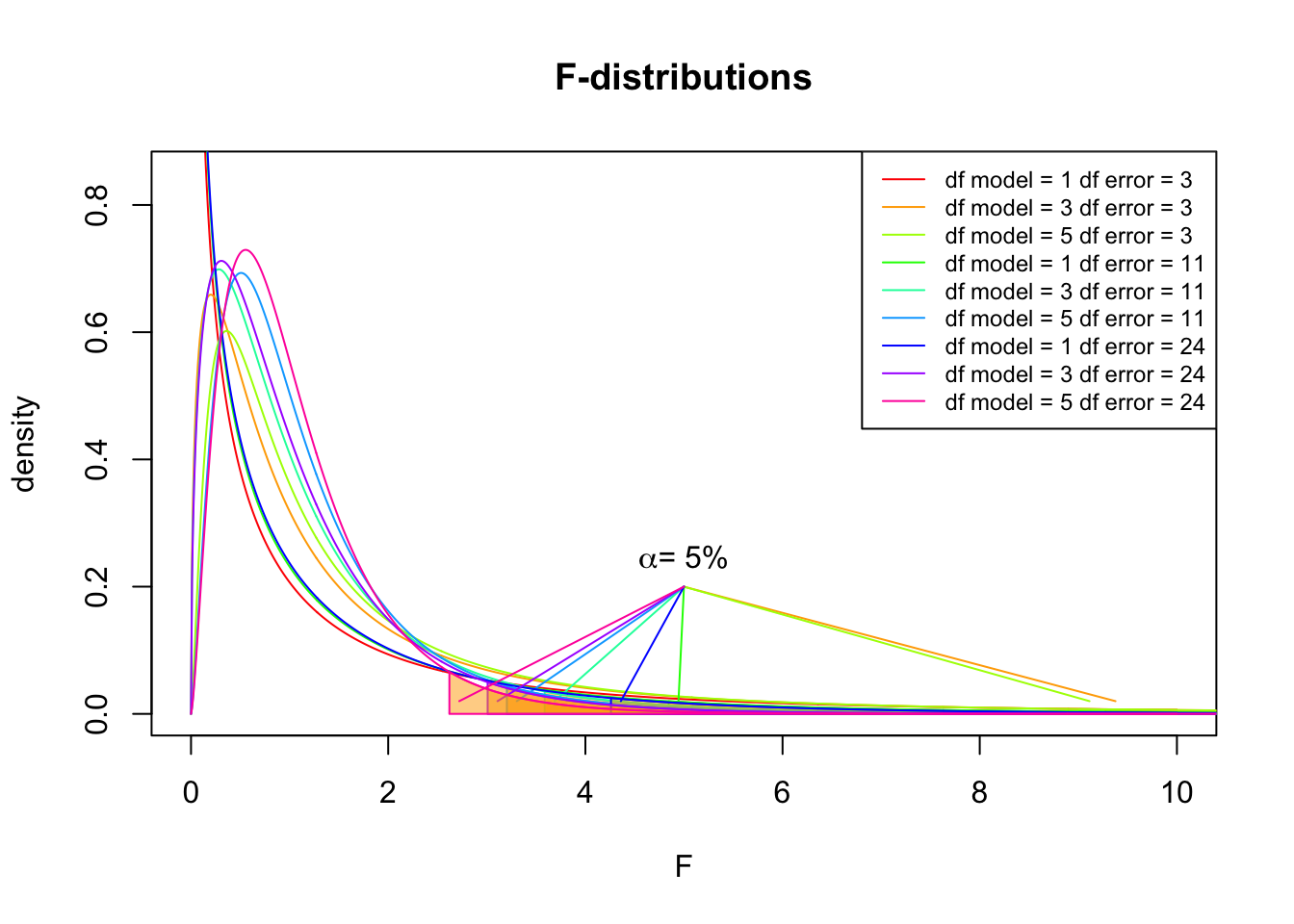
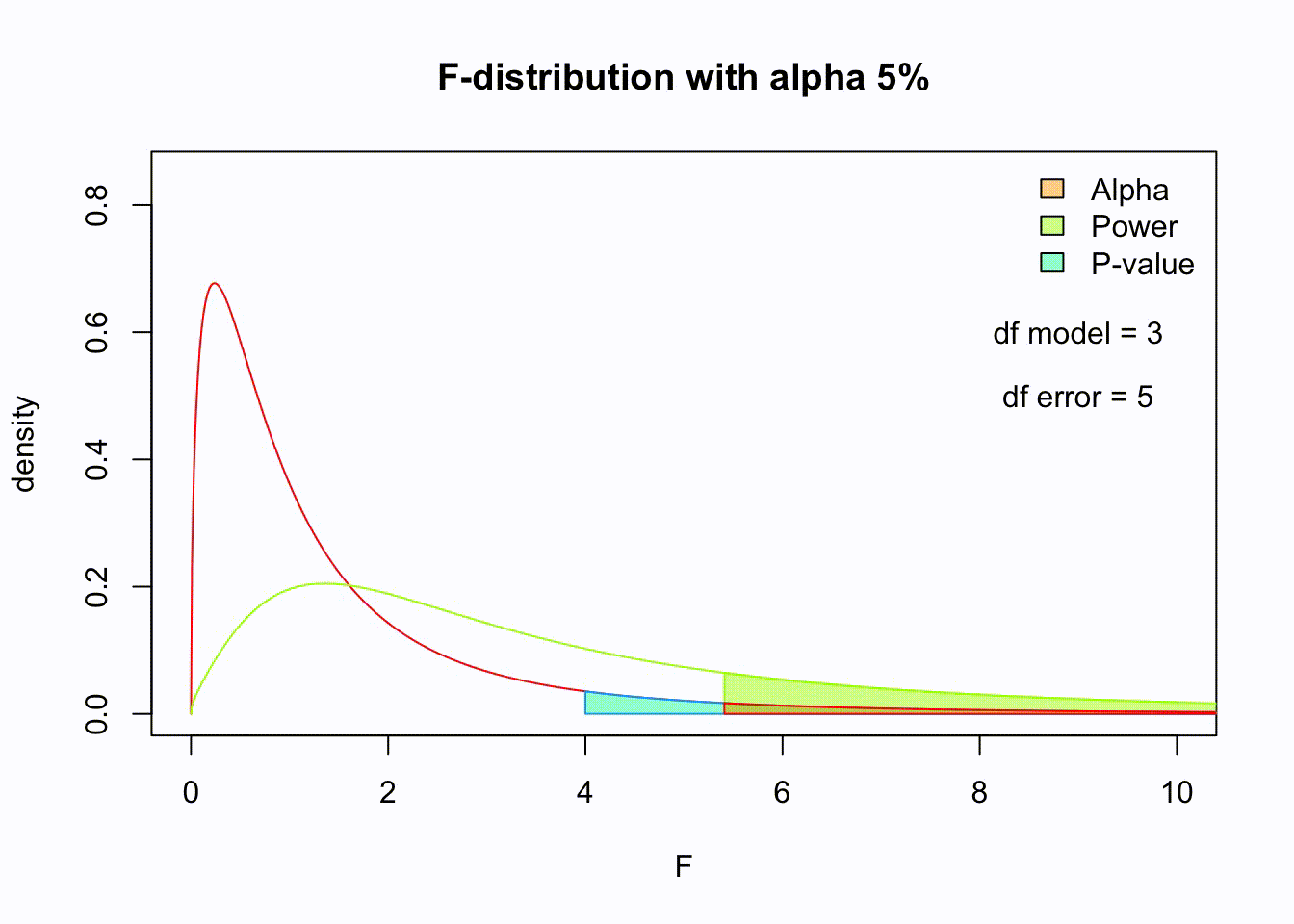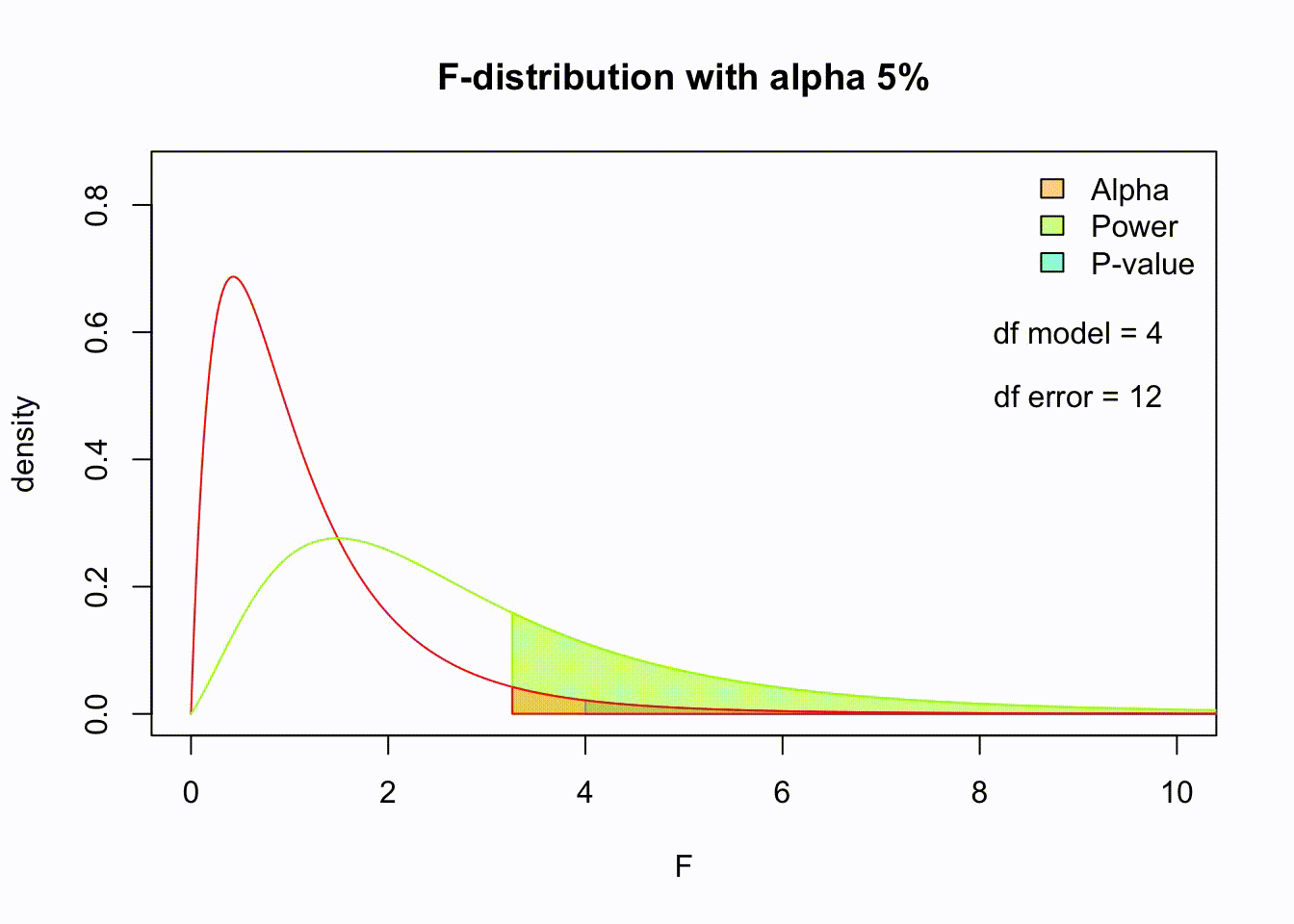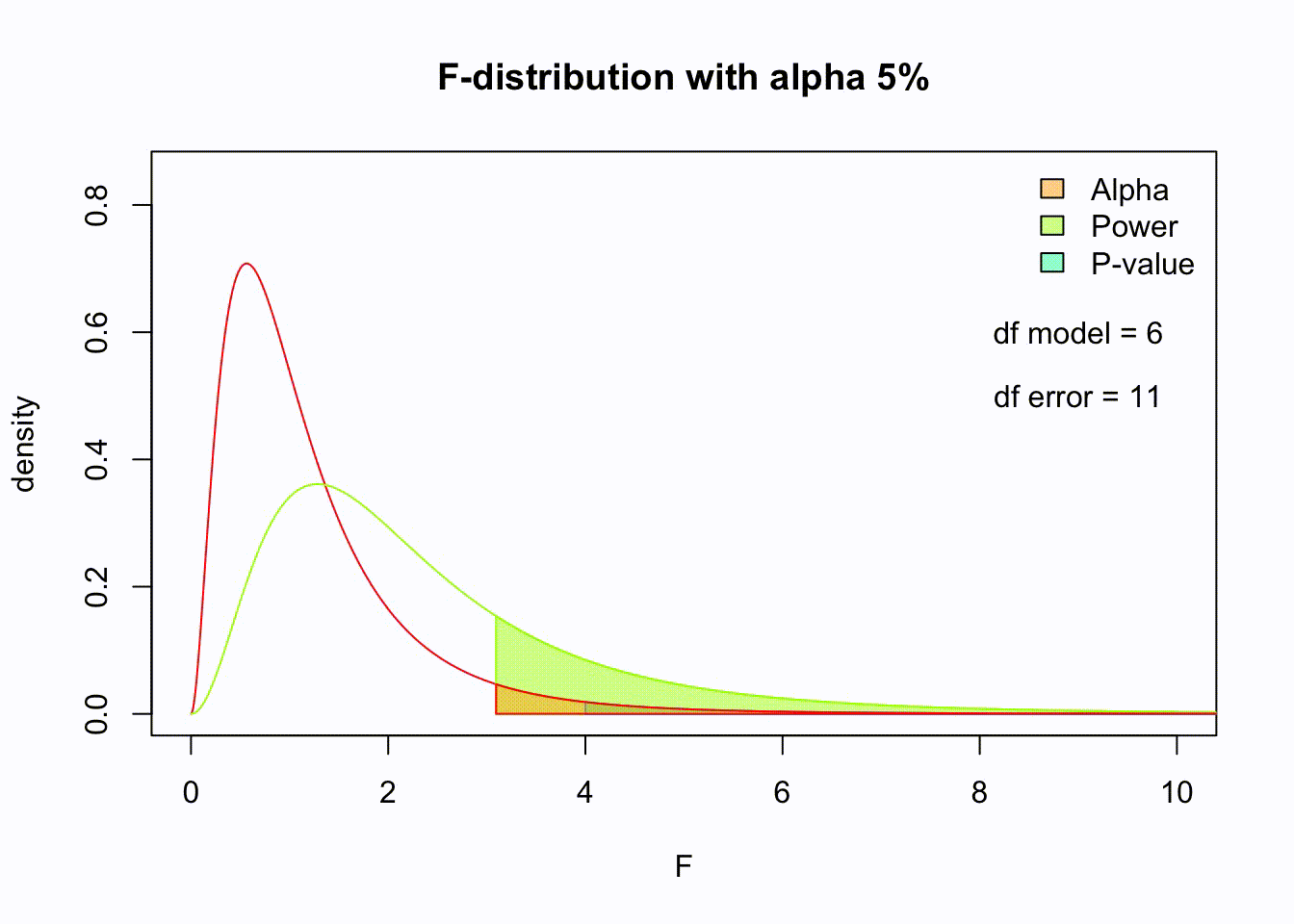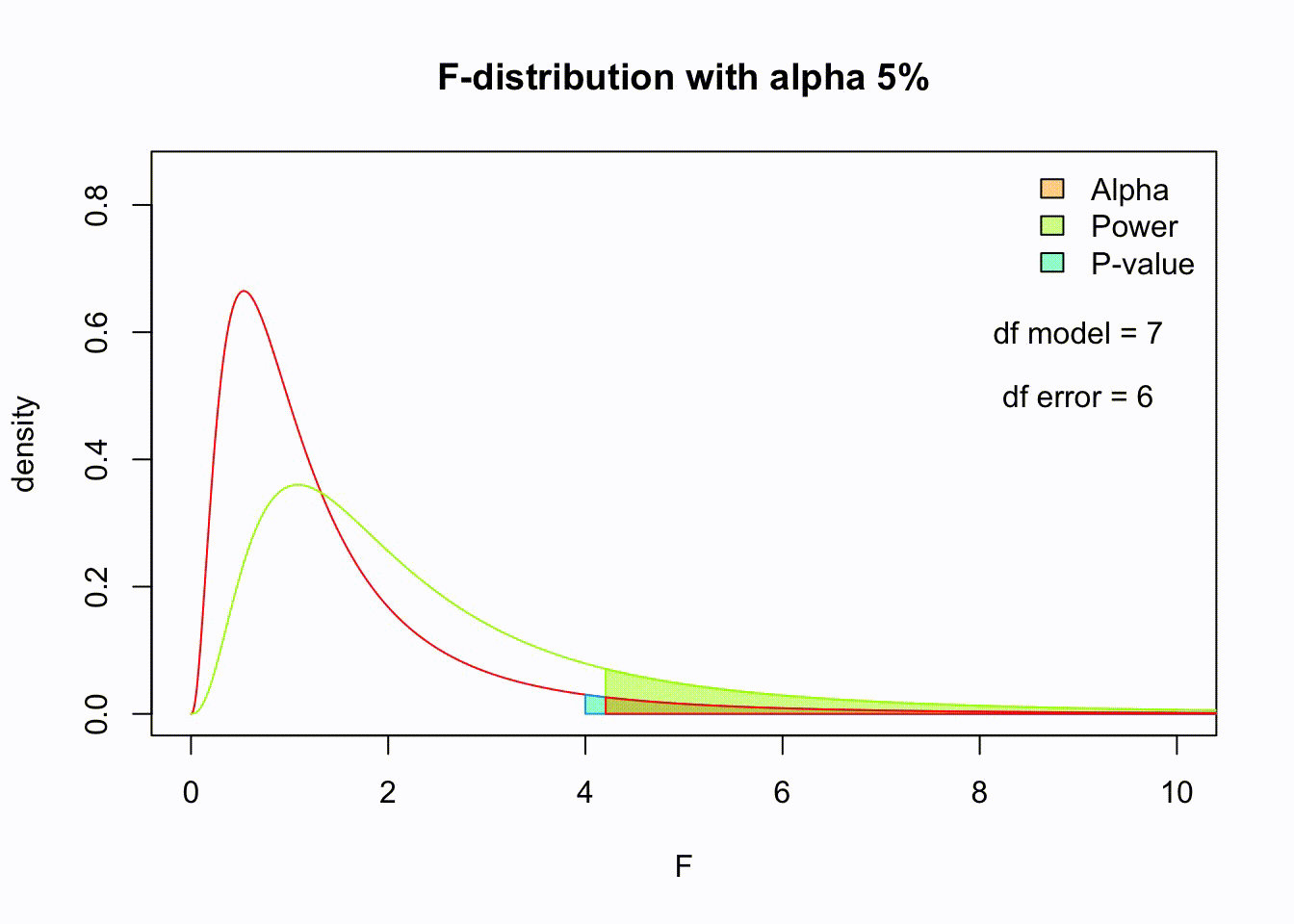
So if the population is normaly distributed (assumption of normality) the f-distribution represents the signal to noise ration given a certain number of samples (\({df}_{model} = k - 1\)) and sample size (\({df}_{error} = N - k\)).
The F-distibution therefore is different for different sample sizes and number of groups.
Assuming th \(H_0\) hypothesis to be true, the following should hold:
Continuous variable
Random sample
Normaly distributed
Shapiro-Wilk test
Equal variance within groups
Levene’s test
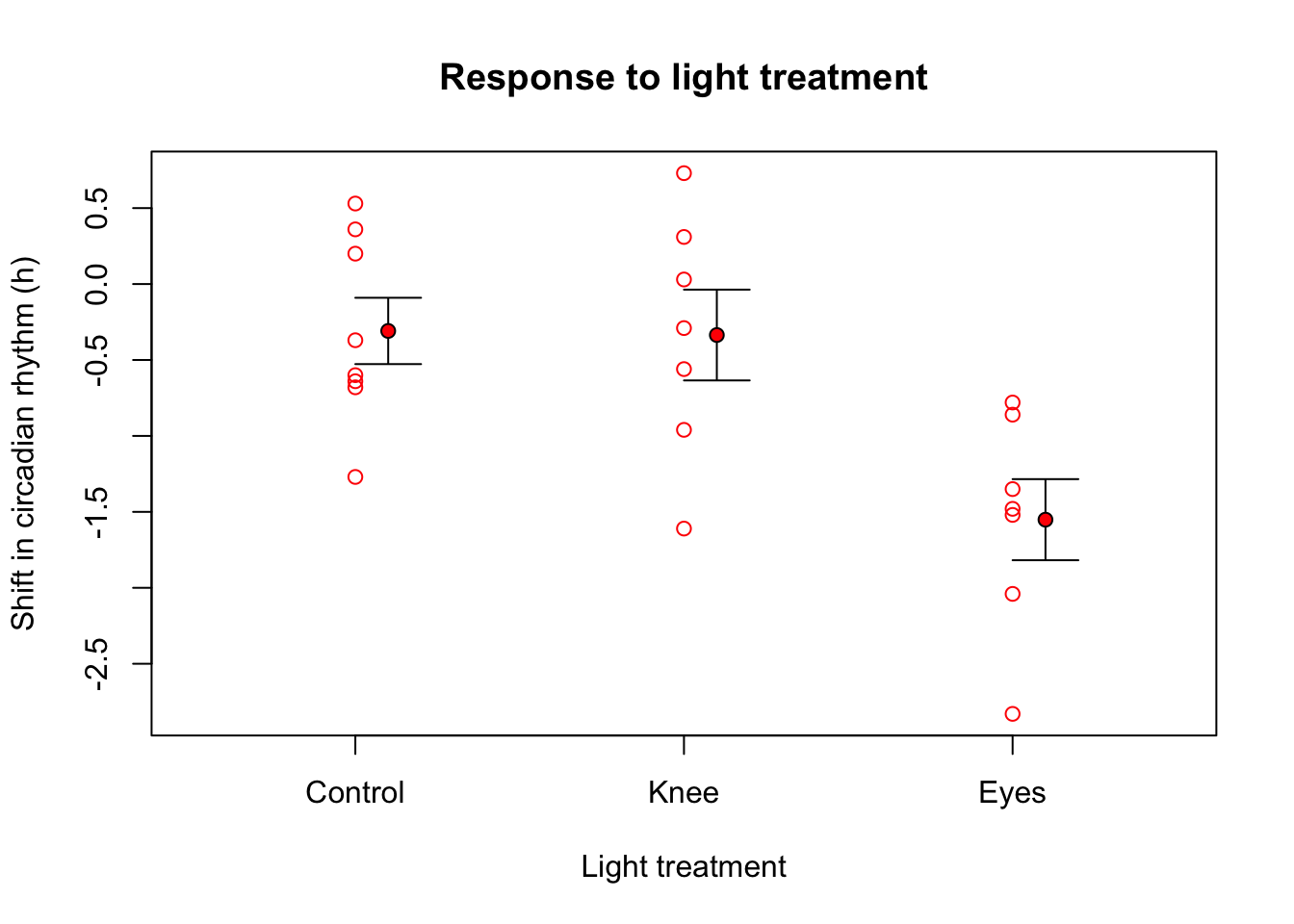
Jet lag
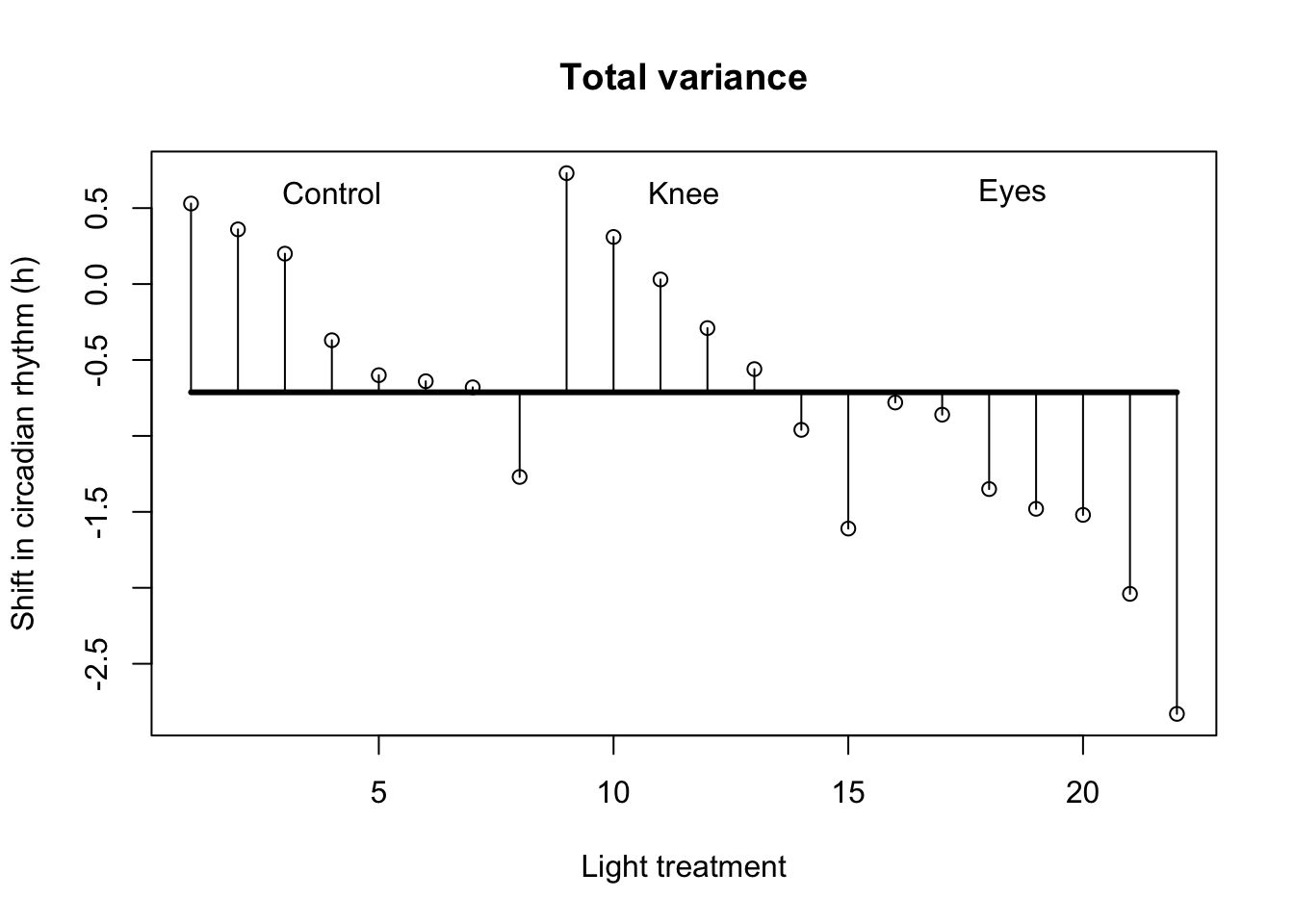
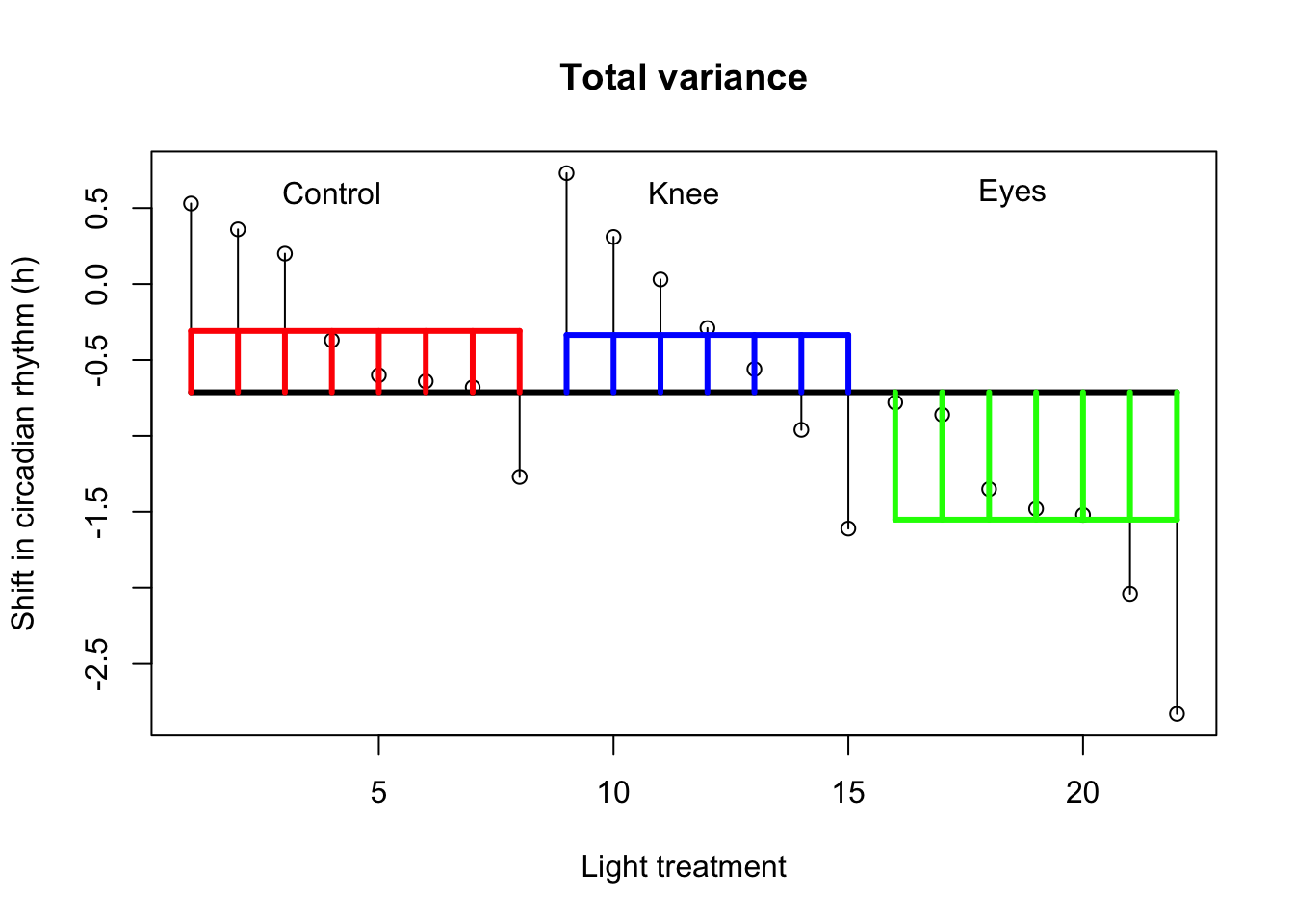
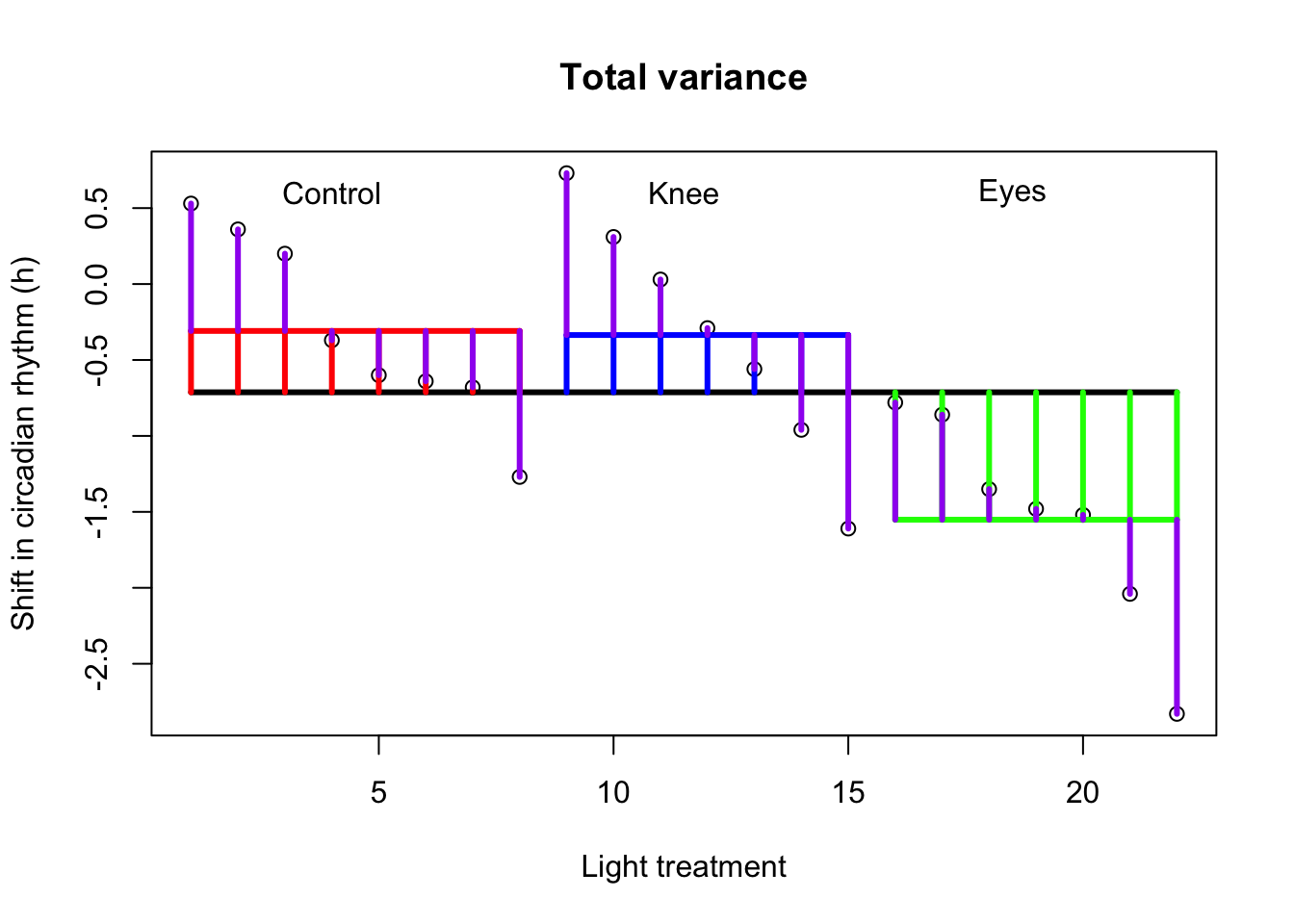
Wright and Czeisler (2002) performed an experiment where they measured the circadian rhythm by the daily cycle of melatonin production in 22 subjects randomly assigned to one of three light treatments.
Where \(N\) is the total sample size, \(n_k\) is the sample size per category and \(k\) is the number of categories. Finally \(s_k^2\) is the variance per category.
Total variance
\[{MS}_{total} = s_x^2\]
ms.t =var(x); ms.t
[1] 0.7923732
sum( (x -mean(x))^2 ) / (length(x) -1)
[1] 0.7923732
\[{SS}_{total} = s_x^2 (N-1)\]
N =length(x)ss.t =var(x) * (N-1); ss.t
[1] 16.63984
sum( (x -mean(x))^2 )
[1] 16.63984
Visual \({SS}_{total}\)
# Assign labelslab =c("Control", "Knee", "Eyes") # Plot all data pointsplot(1:N,x, ylab="Shift in circadian rhythm (h)",xlab="Light treatment",main="Total variance")# Add mean linelines(c(1,22),rep(mean(x),2),lwd=3)# Add delta lines / variance componentssegments(1:N, mean(x), 1:N, x)# Add labelstext(c(4,11.5,18.5),rep(.6,3),labels=lab)
Model variance
\[{MS}_{model} = \frac{{SS}_{model}}{{df}_{model}} \\ {df}_{model} = k - 1\]
Where \(k\) is the number of independent groups and