Correlation and Simple regression
Correlation
Pearson Correlation

In statistics, the Pearson correlation coefficient, also referred to as the Pearson’s r, Pearson product-moment correlation coefficient (PPMCC) or bivariate correlation, is a measure of the linear correlation between two variables X and Y. It has a value between +1 and −1, where 1 is total positive linear correlation, 0 is no linear correlation, and −1 is total negative linear correlation. It is widely used in the sciences. It was developed by Karl Pearson from a related idea introduced by Francis Galton in the 1880s.
Source: Wikipedia
PMCC
\[r_{xy} = \frac{{COV}_{xy}}{S_xS_y}\]
Where \(S\) is sthe standard deviation and \(COV\) is the covariance.
\[{COV}_{xy} = \frac{\sum_{i=1}^N (x_i - \bar{x})(y_i - \bar{y})}{N-1}\]
Plot correlation
set.seed(565433)
x = rnorm(10, 5)
y = rnorm(10, 5)
plot(x, y, las = 1)
m.x = mean(x)
m.y = mean(y)
polygon(c(m.x,8,8,m.x),c(m.y,m.y,8,8), col = rgb(0,.64,0,.5))
polygon(c(m.x,0,0,m.x),c(m.y,m.y,0,0), col = rgb(0,.64,0,.5))
polygon(c(m.x,0,0,m.x),c(m.y,m.y,8,8), col = rgb(1,.55,0,.5))
polygon(c(m.x,8,8,m.x),c(m.y,m.y,0,0), col = rgb(1,.55,0,.5))
points(x,y)
abline(h = m.y, lwd = 3)
abline(v = m.x, lwd = 3)
segments(x, m.y, x, y, col = "orange", lwd = 2)
segments(x, y, m.x, y, col = "darkgreen", lwd = 2)
text(m.x+.7, m.y+.7, "+ x +", cex = 2)
text(m.x-.7, m.y-.7, "- x -", cex = 2)
text(m.x+.7, m.y-.7, "+ x -", cex = 2)
text(m.x-.7, m.y+.7, "- x +", cex = 2)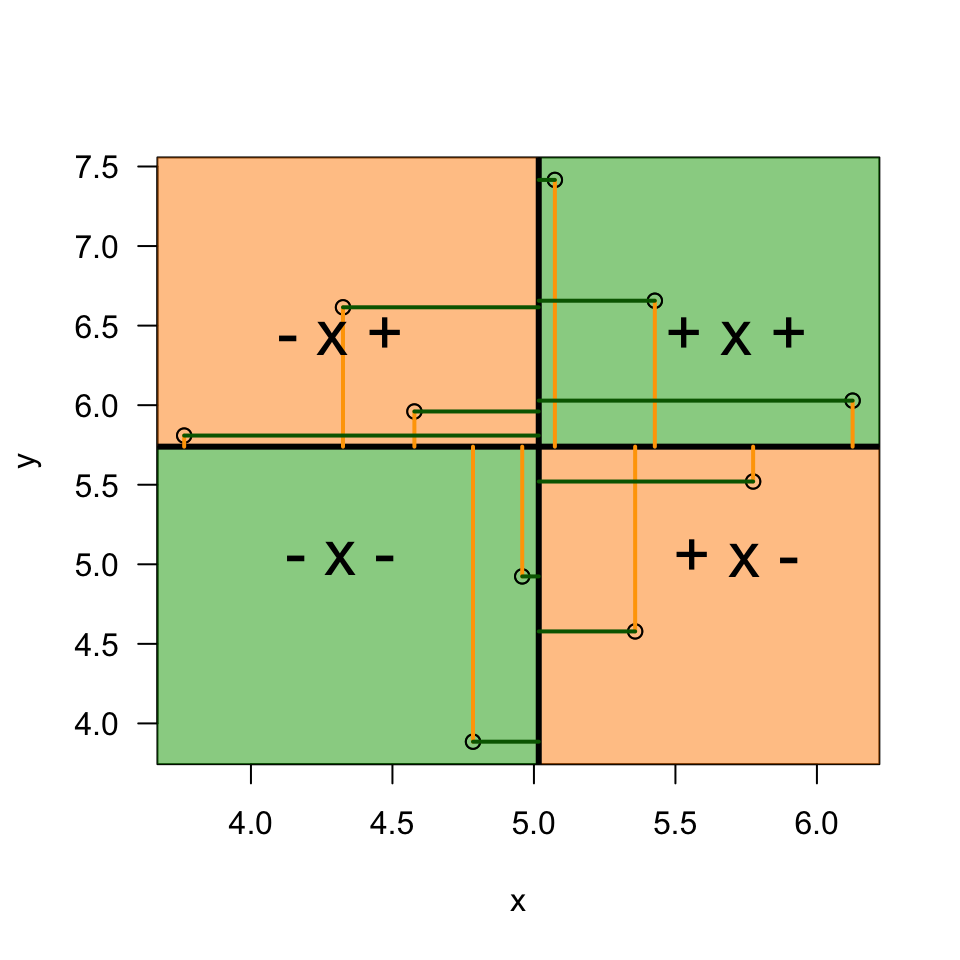
\[(x_i - \bar{x})(y_i - \bar{y})\]
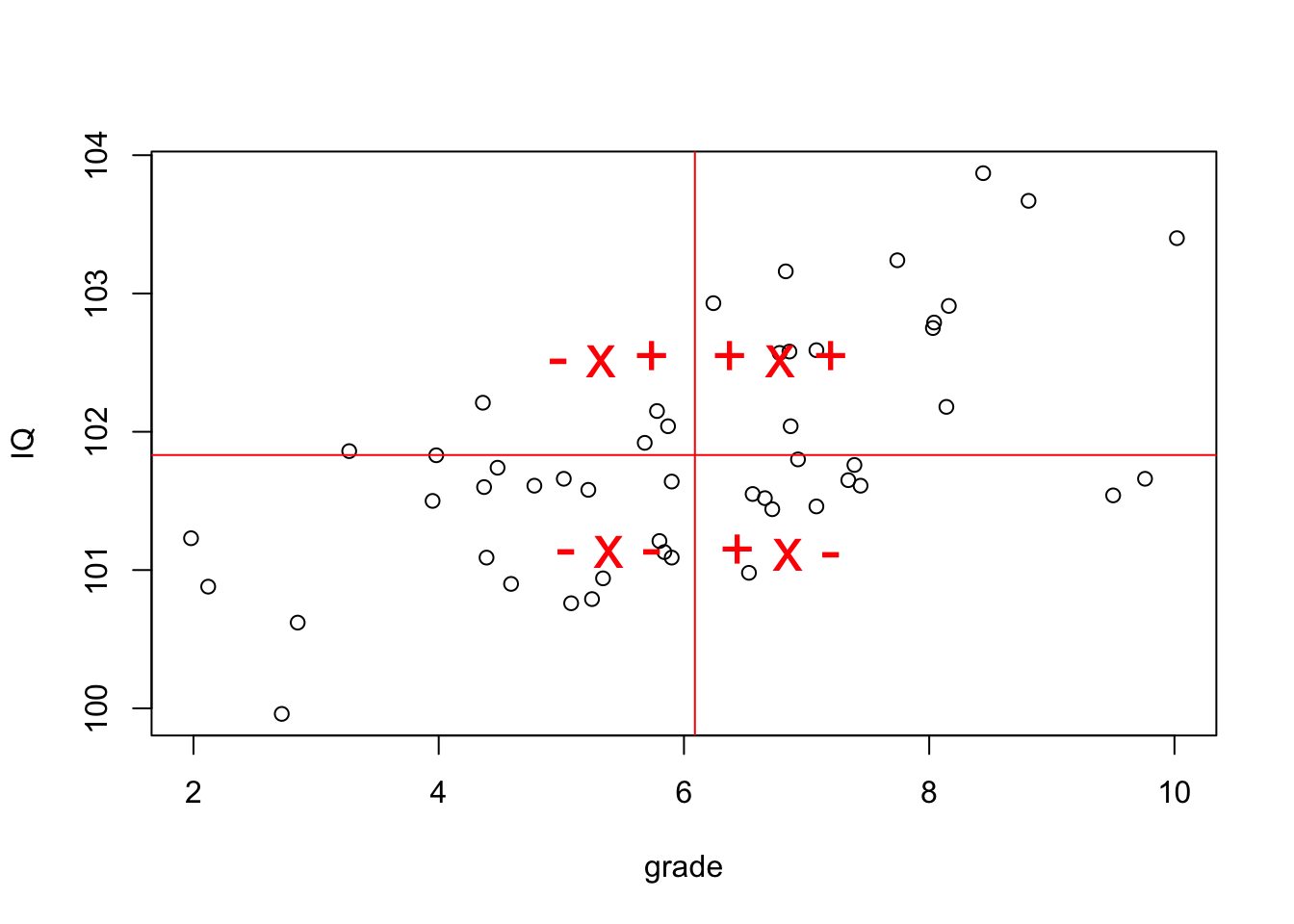
Guess the correlation


Simulate data
n = 50
grade = rnorm(n, 6, 1.6)
b.0 = 100
b.1 = .3
error = rnorm(n, 0, 0.7)
IQ = b.0 + b.1 * grade + error
#IQ = group(IQ)
error = rnorm(n, 0, 0.7)
motivation = 3.2 + .2 * IQ + errorExplaining vairance
grade = data$grade
IQ = data$IQ
mean.grade = mean(grade)
mean.IQ = mean(IQ)
N = length(grade)
plot(data$grade, ylim=summary(c(data$grade, data$IQ))[c('Min.','Max.')],
col='orange',
ylab="variables",
xlab="People")
points(data$IQ, col='blue')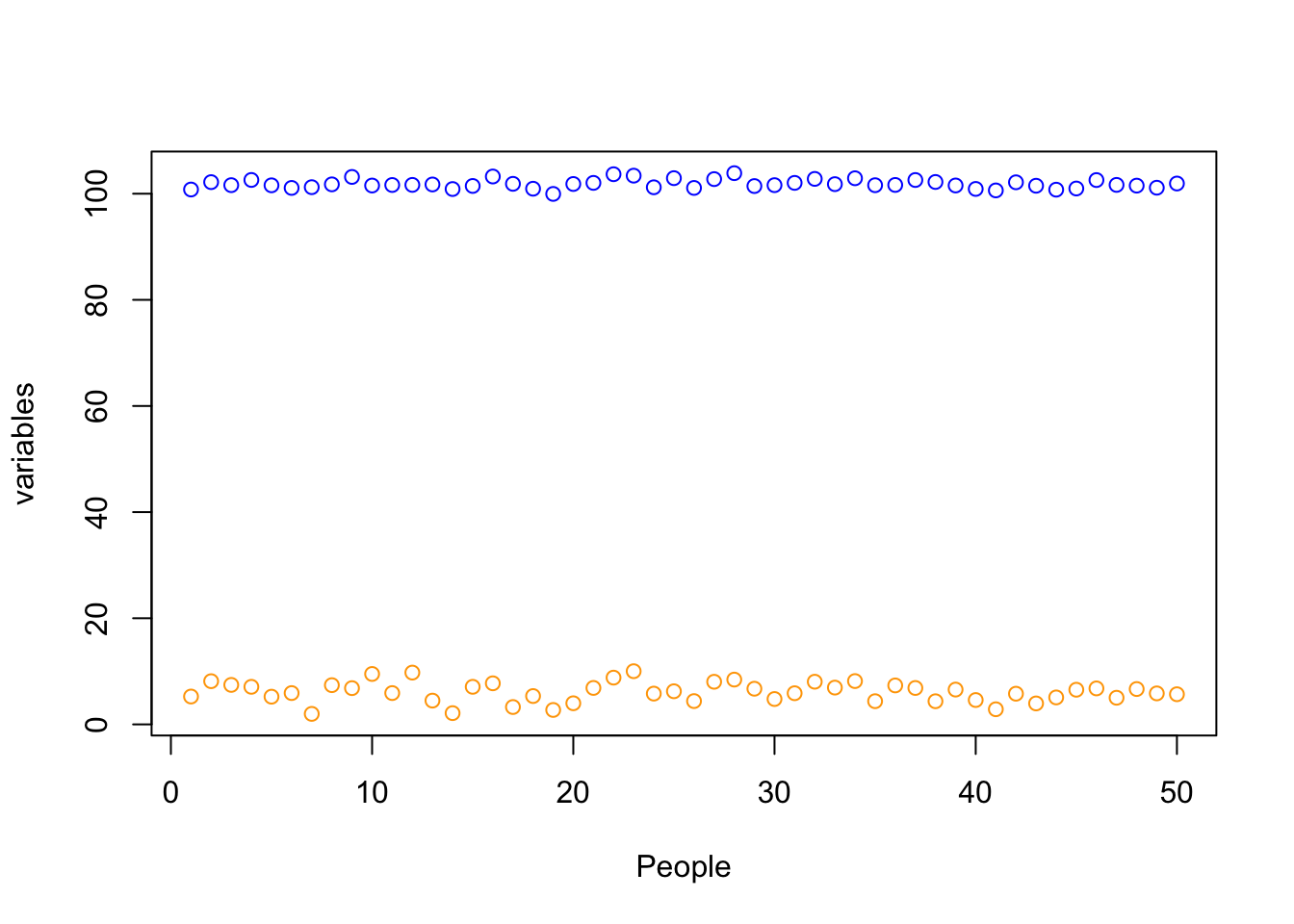
Standarize
\[z = \frac{x_i - \bar{x}}{{sd}_x}\]
data[, c('z.grade', 'z.IQ')] = scale(data[, c('grade', 'IQ')])
z.grade = data$z.grade
z.IQ = data$z.IQ
mean.z.grade = mean(z.grade, na.rm=T)
mean.z.IQ = mean(z.IQ, na.rm=T)
plot(z.grade,
ylim = summary(c(z.grade, z.IQ))[c('Min.','Max.')],
col = 'orange',
ylab = "", xlab="participants")
points(z.IQ, col='blue')
# Add mean lines
lines(rep(mean.z.grade, N), col='orange')
lines(rep(mean.z.IQ, N), col='blue', lt=2)
# Add vertical variance lines
segments(1:N, mean.z.grade, 1:N, z.grade, col='orange')
segments(1:N, mean.z.IQ, 1:N, z.IQ, col='blue')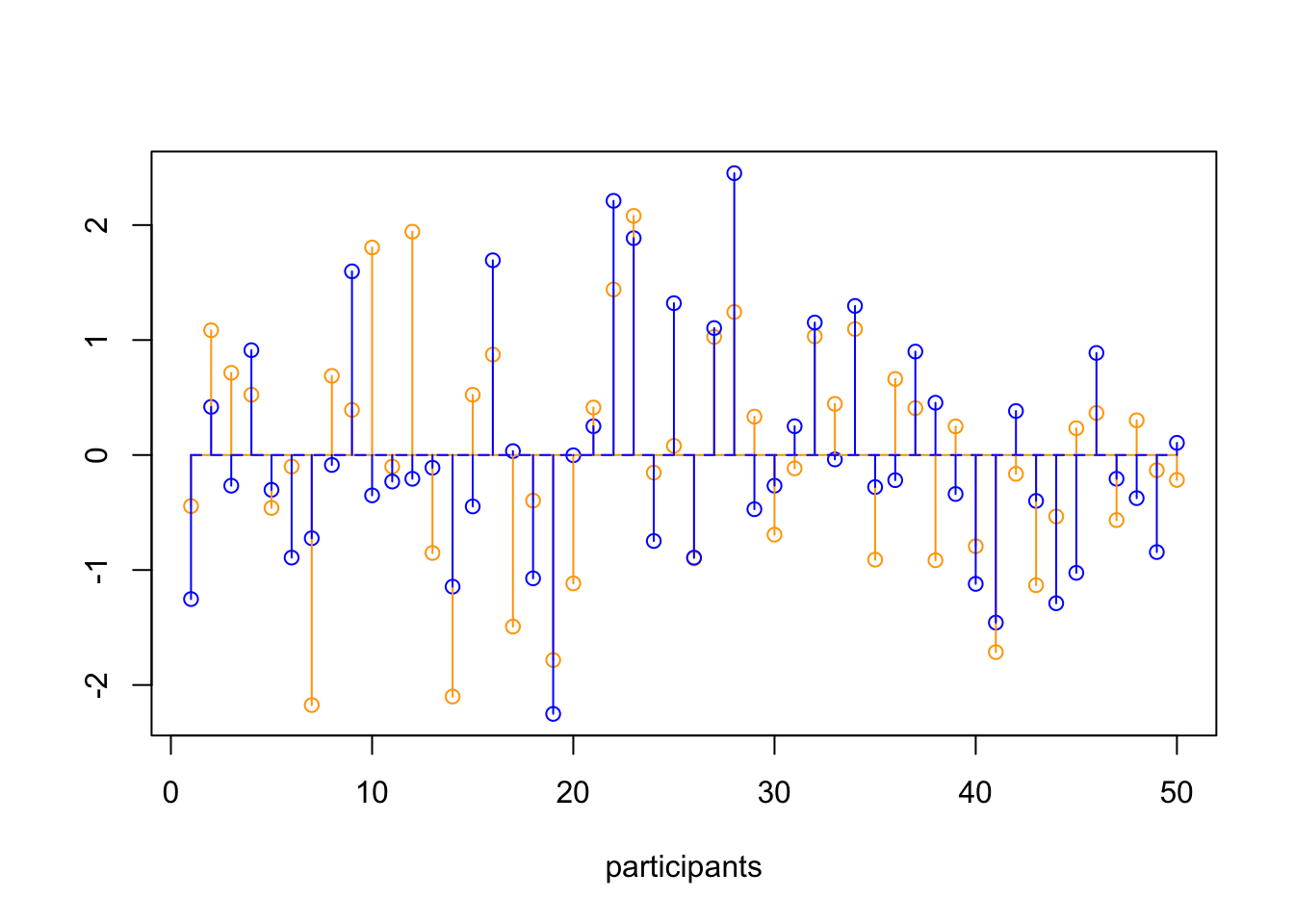
Covariance
\[{COV}_{xy} = \frac{\sum_{i=1}^N (x_i - \bar{x})(y_i - \bar{y})}{N-1}\]
mean.grade = mean(grade, na.rm=T)
mean.IQ = mean(IQ, na.rm=T)
delta.grade = grade - mean.grade
delta.IQ = IQ - mean.IQ
prod = (grade - mean.grade) * (IQ - mean.IQ)
covariance = sum(prod) / (N - 1)Correlation
\[r_{xy} = \frac{{COV}_{xy}}{S_xS_y}\]
correlation = covariance / ( sd(grade) * sd(IQ) ); correlation[1] 0.6207285cor(z.grade, z.IQ)[1] 0.6207285cor( grade, IQ)[1] 0.6207285sum( z.grade * z.IQ ) / (N - 1)[1] 0.6207285x = c(1,-1,-1, 0,.5,-.5)
y = c(1,-1, 1, 1, 1, 1)
cbind(x,y,x*y) x y
[1,] 1.0 1 1.0
[2,] -1.0 -1 1.0
[3,] -1.0 1 -1.0
[4,] 0.0 1 0.0
[5,] 0.5 1 0.5
[6,] -0.5 1 -0.5Plot correlation
Significance of a correlation
\[t_r = \frac{r \sqrt{N-2}}{\sqrt{1 - r^2}} \\ {df} = N - 2\]
$$
\[\begin{aligned} H_0 &: t_r = 0 \\ H_A &: t_r \neq 0 \\ H_A &: t_r > 0 \\ H_A &: t_r < 0 \\ \end{aligned}\]$$
r to t
df = N-2
t.r = ( correlation*sqrt(df) ) / sqrt(1-correlation^2)
cbind(t.r, df) t.r df
[1,] 5.485195 48Visualize
One-sample t-test
if(!"visualize" %in% installed.packages()) { install.packages("visualize") }
library("visualize")
visualize.t(c(-t.r, t.r),df,section='tails')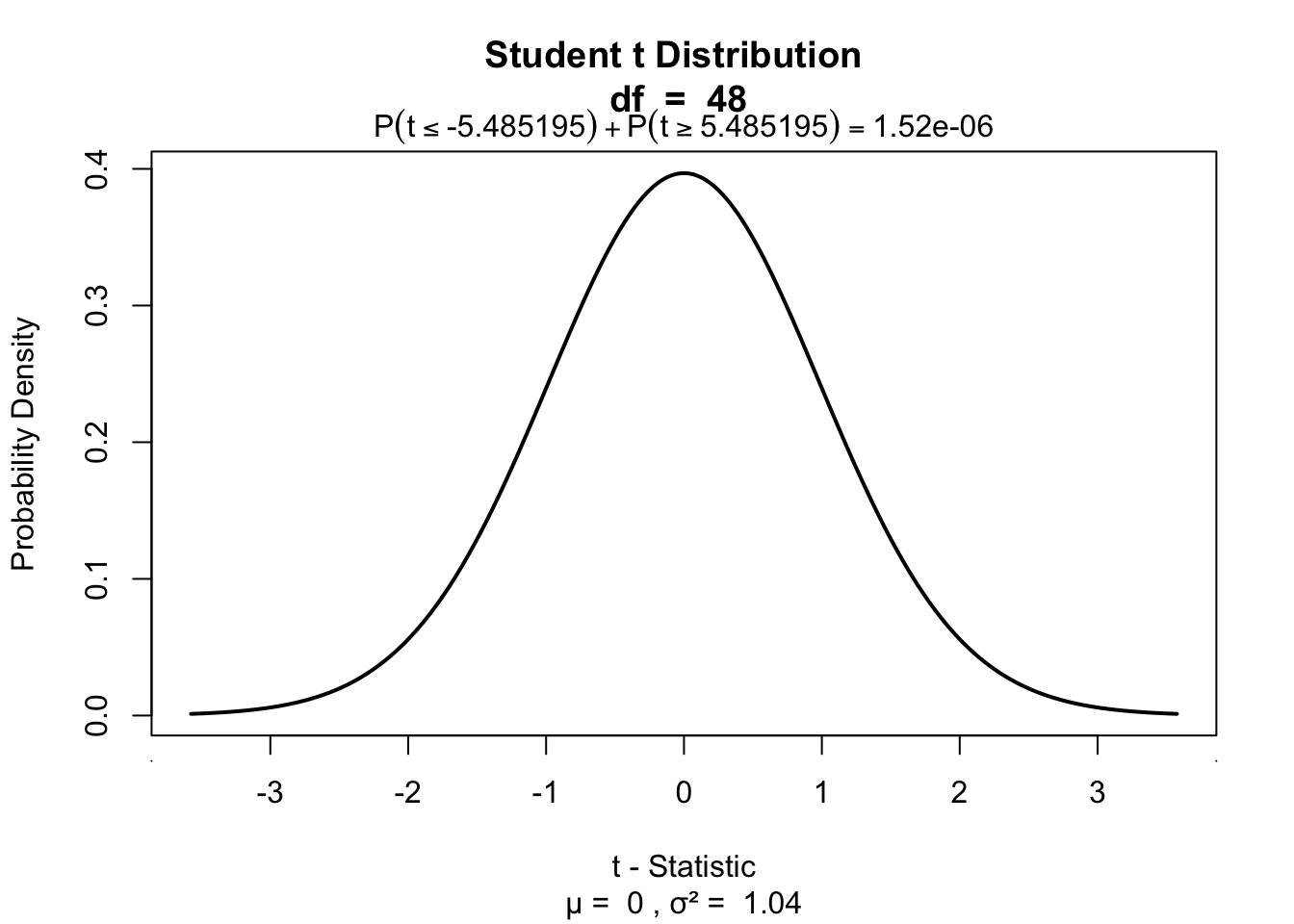
Partial correlation
Venn diagram
Partial correlation
\[\LARGE{r_{xy \cdot z} = \frac{r_{xy} - r_{xz} r_{yz}}{\sqrt{(1 - r_{xz}^2)(1 - r_{yz}^2)}}}\]
motivation = data$motivation
cor.grade.IQ = cor(grade,IQ)
cor.grade.motivation = cor(grade,motivation)
cor.IQ.motivation = cor(IQ,motivation)
data.frame(cor.grade.IQ, cor.grade.motivation, cor.IQ.motivation) cor.grade.IQ cor.grade.motivation cor.IQ.motivation
1 0.6207285 -0.1100721 0.2311468numerator = cor.grade.IQ - (cor.grade.motivation * cor.IQ.motivation)
denominator = sqrt( (1-cor.grade.motivation^2)*(1-cor.IQ.motivation^2) )
partial.correlation = numerator / denominator
partial.correlation[1] 0.6682178Significance of parial correlation
One-sample t-test
df = N - 3
t.pr = ( partial.correlation*sqrt(df) ) / sqrt(1-partial.correlation^2)
t.pr[1] 6.157636visualize.t(c(-t.pr,t.pr),df,section='tails')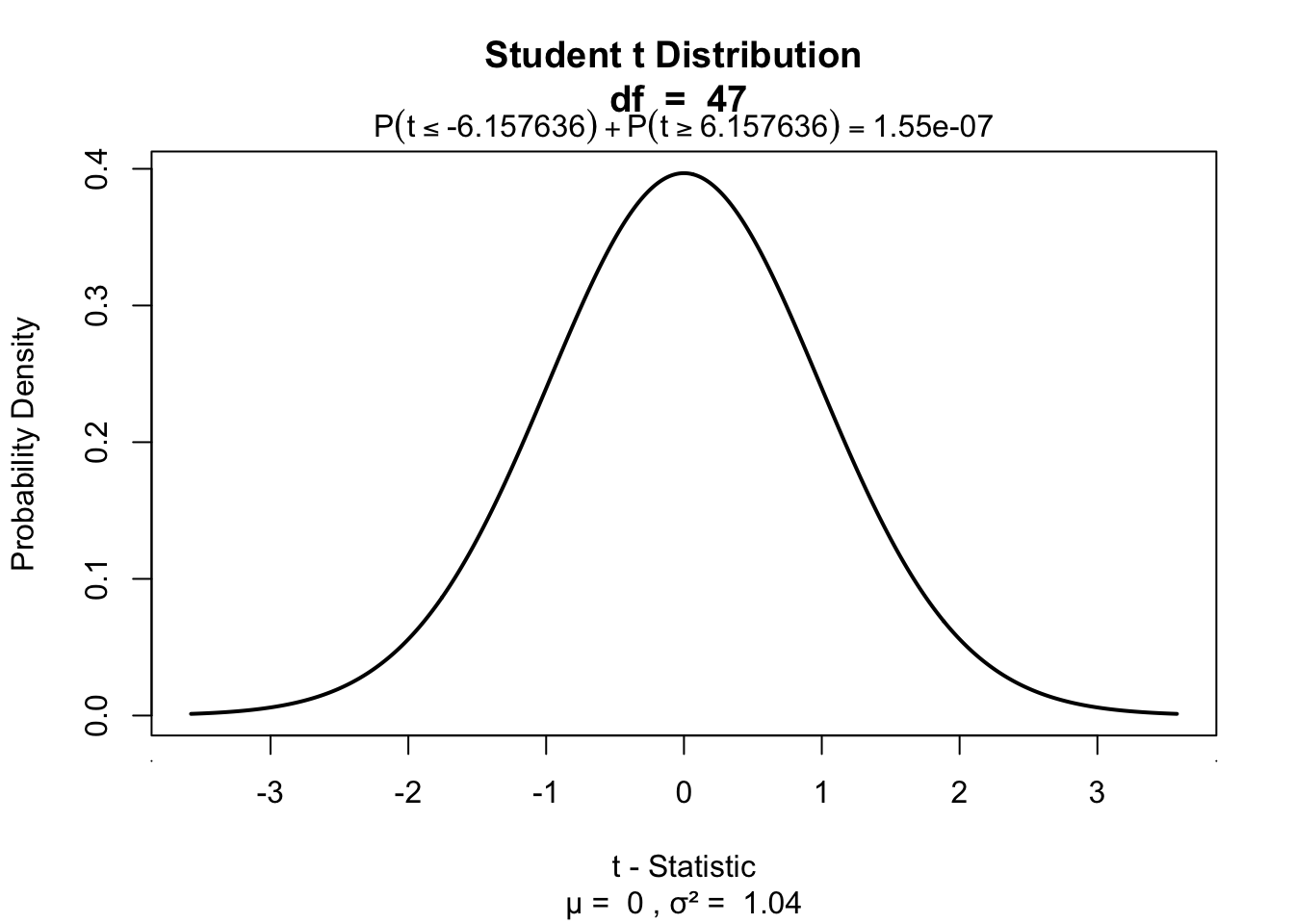
Regression
(one predictor)
Regression
\[\LARGE{\text{outcome} = \text{model} + \text{error}}\]
In statistics, linear regression is a linear approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables denoted X. The case of one explanatory variable is called simple linear regression.
\[\LARGE{Y_i = \beta_0 + \beta_1 X_i + \epsilon_i}\]
In linear regression, the relationships are modeled using linear predictor functions whose unknown model parameters are estimated from the data.
Source: wikipedia
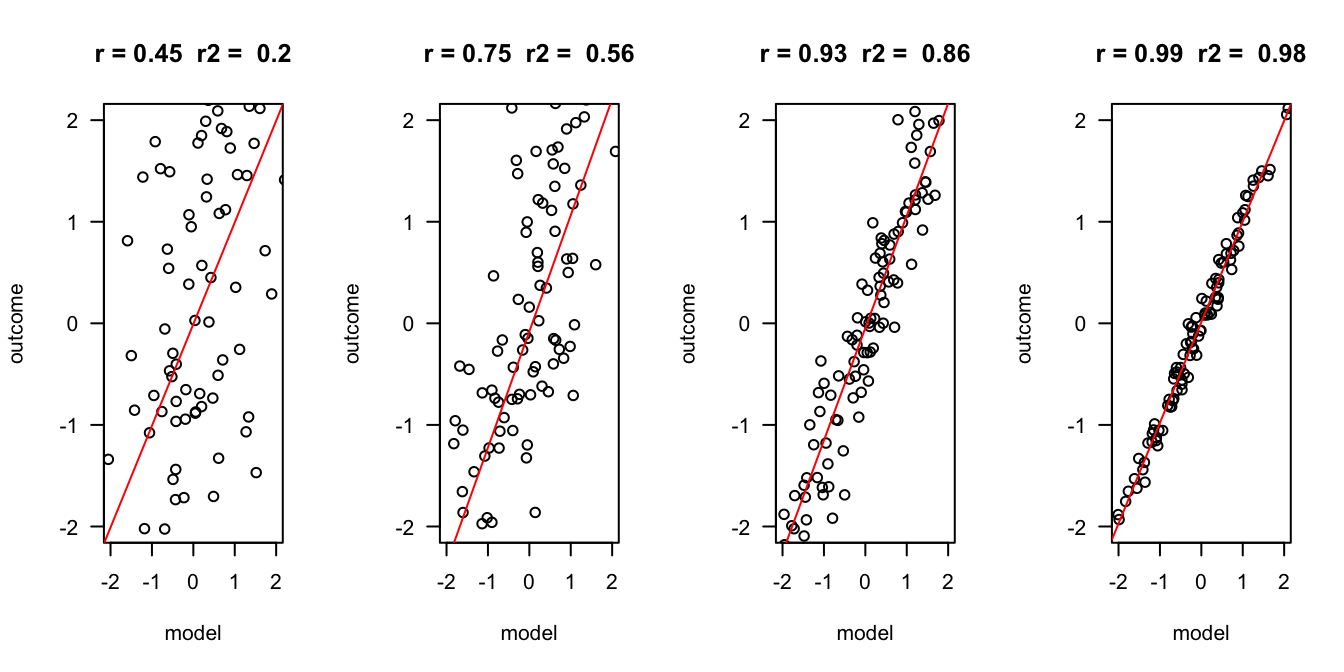
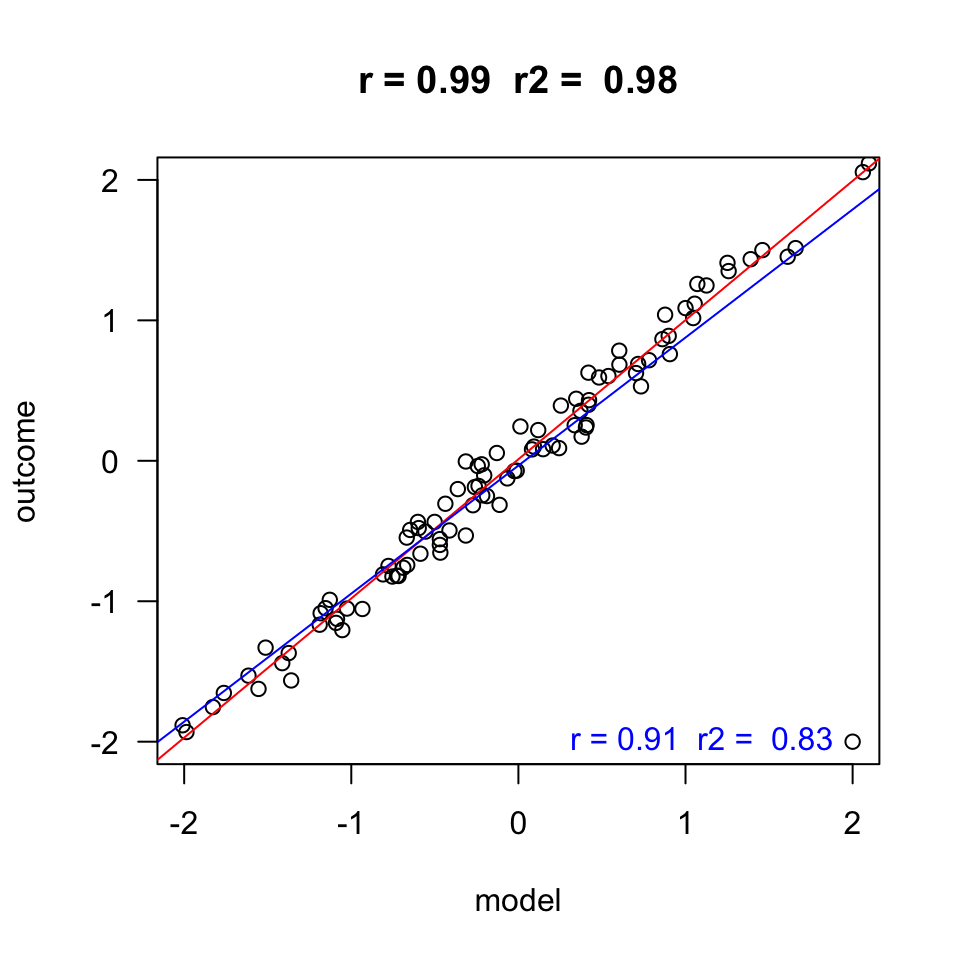
Outcome vs Model
error = c(2, 1, .5, .1)
n = 100
layout(matrix(1:4,1,4))
for(e in error) {
x = rnorm(n)
y = x + rnorm(n, 0 , e)
r = round(cor(x,y), 2)
r.2 = round(r^2, 2)
plot(x,y, las = 1, ylab = "outcome", xlab = "model", main = paste("r =", r," r2 = ", r.2), ylim=c(-2,2), xlim=c(-2,2))
fit <- lm(y ~ x)
abline(fit, col = "red")
}
Assumptions
A selection from Field:
- Sensitivity
- Homoscedasticity
Sensitivity
Outliers
- Extreme residuals
- Cook’s distance (< 1)
- Mahalonobis (< 11 at N = 30)
- Laverage (The average leverage value is defined as (k + 1)/n)
Homoscedasticity
- Variance of residual should be equal across all expected values
- Look at scatterplot of standardized: expected values \(\times\) residuals. Roughly round shape is needed.
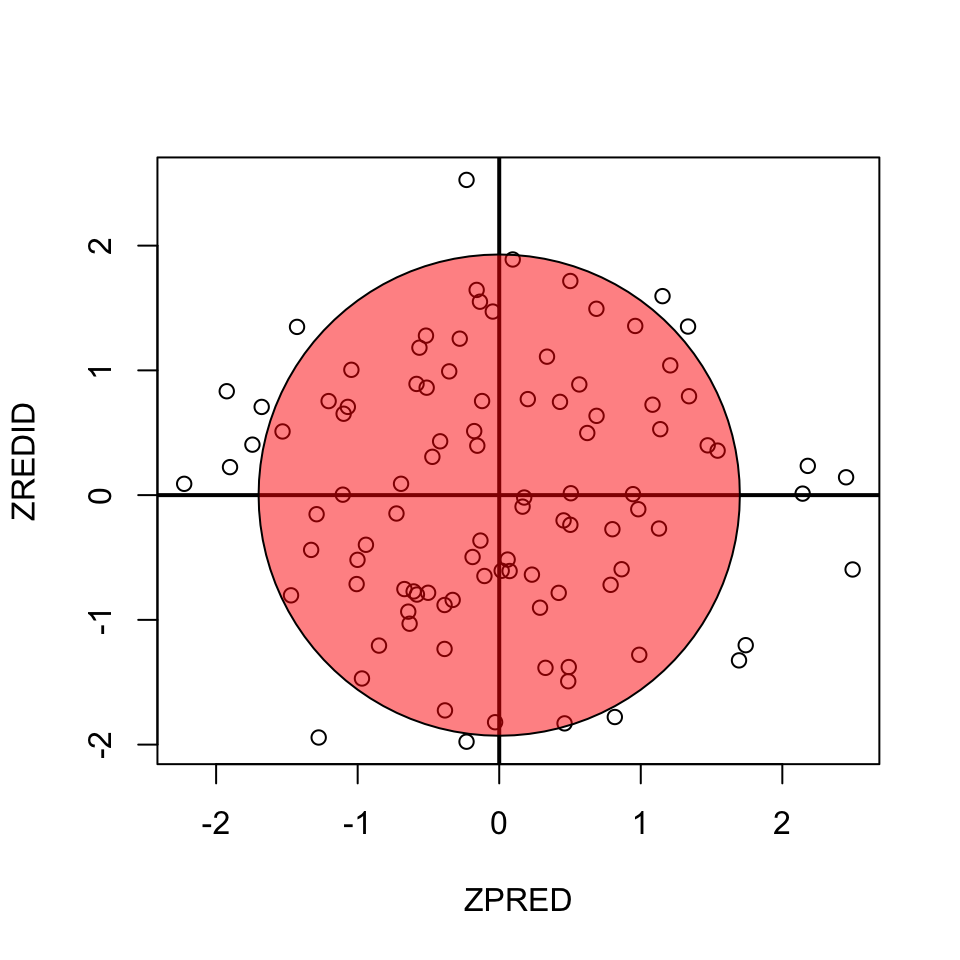
Simulation
set.seed(28736)
N = 123
mu = 120
sigma = 15
IQ = rnorm(N, mu, sigma)
b_0 = 1
b_1 = .04
error = rnorm(N, 0, 1)
grade = b_0 + b_1 * IQ + error
data = data.frame(grade, IQ)
data = round(data, 2)
# Write data for use in SPSS
write.table(data, "IQ.csv", row.names=FALSE, col.names=TRUE, dec='.')The data
Calculate regression parameters
\[{grade}_i = b_0 + b_1 {IQ}_i + \epsilon_i\]
IQ = data$IQ
grade = data$gradeCalculate \(b_1\)
\[b_1 = r_{xy} \frac{s_y}{s_x}\]
# Calculate b1
cor.grade.IQ = cor(grade,IQ)
sd.grade = sd(grade)
sd.IQ = sd(IQ)
b1 = cor.grade.IQ * ( sd.grade / sd.IQ )
b1[1] 0.04489104Calculate \(b_0\)
\[b_0 = \bar{y} - b_1 \bar{x}\]
mean.grade = mean(grade)
mean.IQ = mean(IQ)
b0 = mean.grade - b1 * mean.IQ
b0[1] 0.4167131The slope
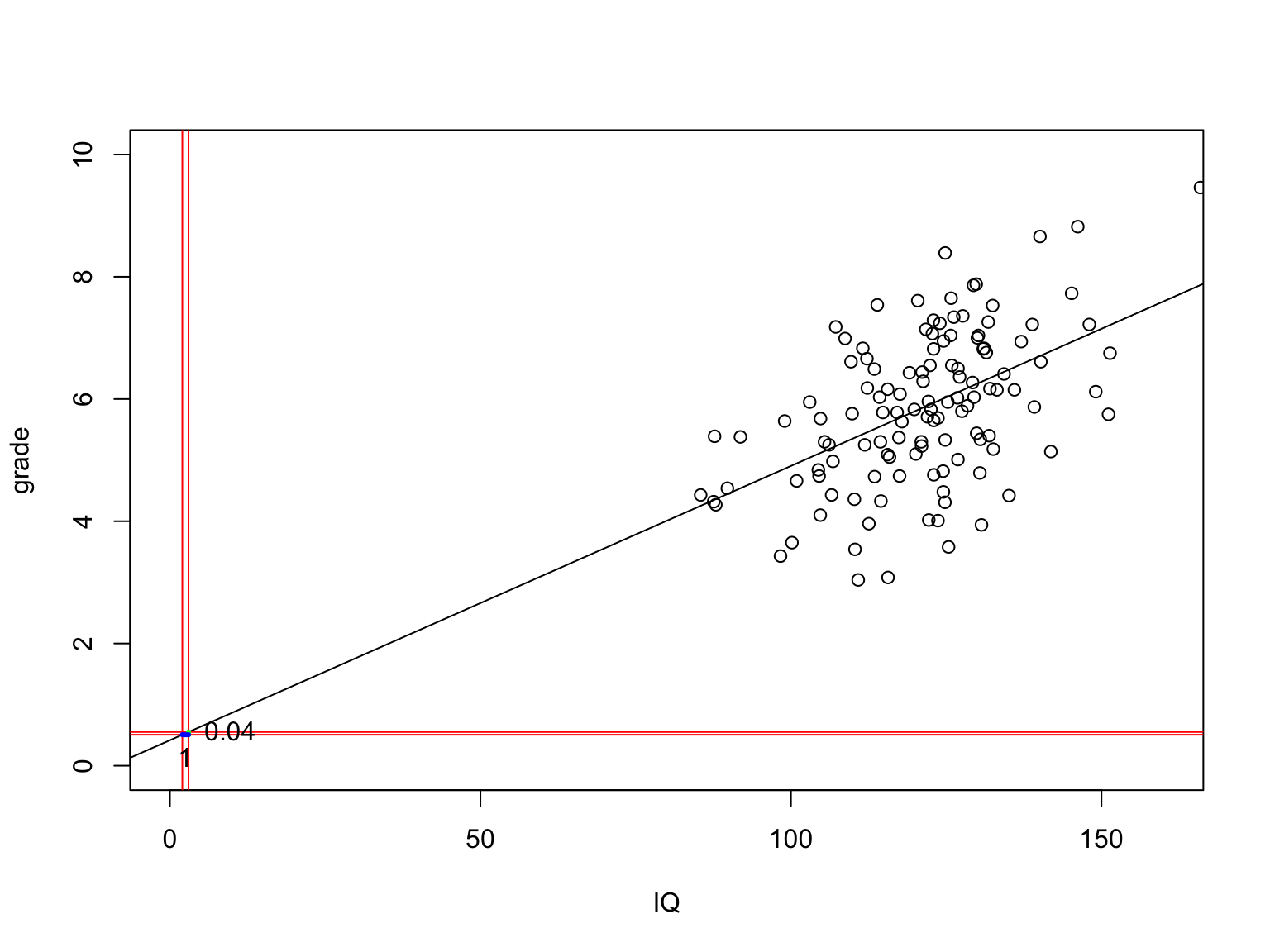
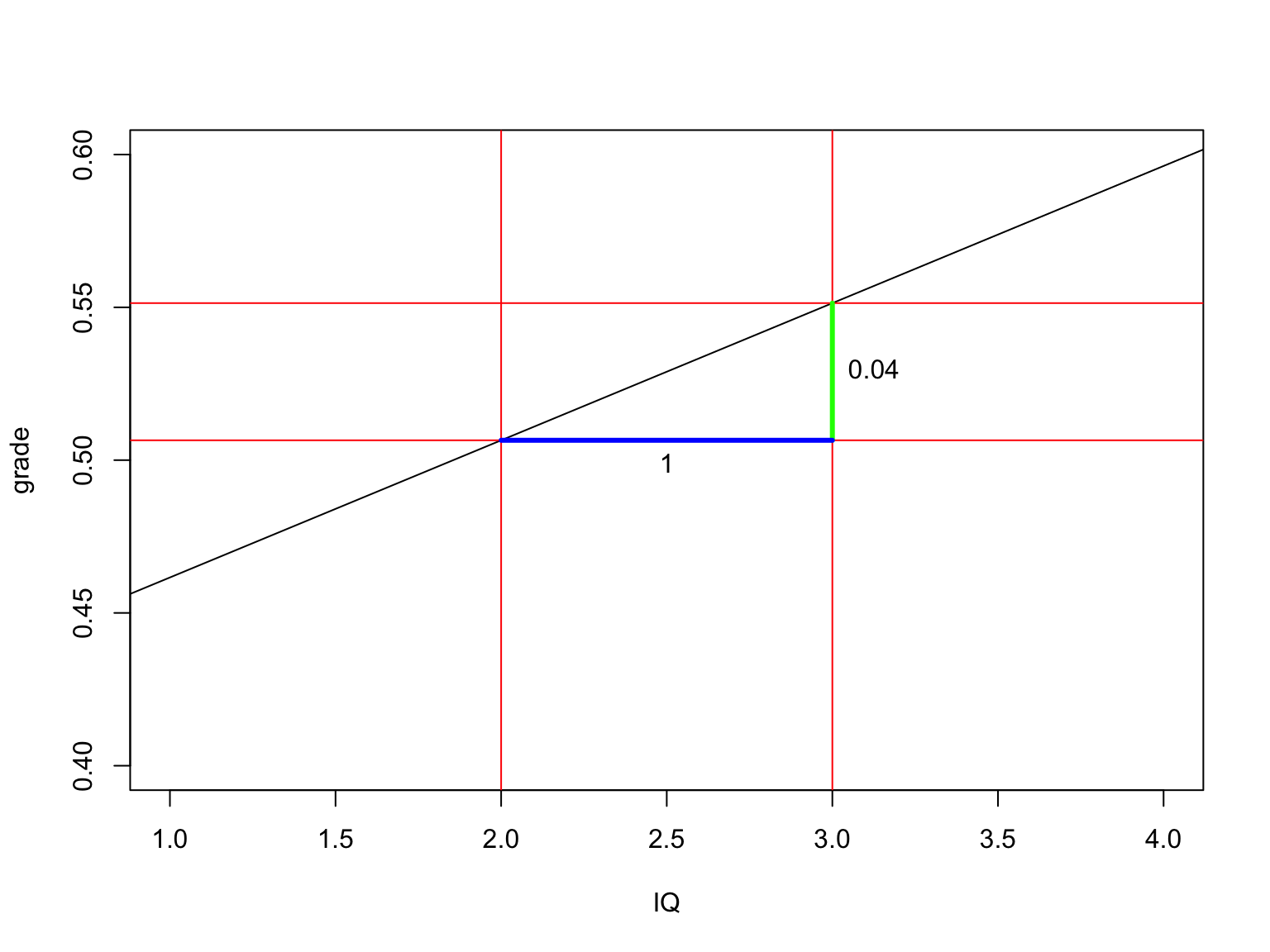
Calculate t-values for b’s
\[t_{n-p-1} = \frac{b - \mu_b}{{SE}_b}\]
Where \(n\) is the number of rows, \(p\) is the number of predictors, \(b\) is the beta coefficient and \({SE}_b\) its standard error.
# Get Standard error's for b
fit <- lm(grade~IQ)
se = summary(fit)[4]$coefficients[,2]
se.b0 = se[1]
se.b1 = se[2]
cbind(se.b0, se.b1) se.b0 se.b1
(Intercept) 0.8542378 0.006998539# Calculate t's
mu.b0 = 0
mu.b1 = 0
t.b0 = (b0 - mu.b0) / se.b0; t.b0(Intercept)
0.4878187 t.b1 = (b1 - mu.b1) / se.b1; t.b1 IQ
6.414345 n = nrow(data) # number of rows
p = 1 # number of predictors
df.b0 = n - p - 1
df.b1 = n - p - 1P-values of \(b_0\)
$$ \[\begin{aligned} t_{n-p-1} &= \frac{b - \mu_b}{{SE}_b} \\ df &= n - p - 1 \\ \end{aligned}\]$$
Where \(b\) is het beta coeficient \({SE}\) is the standard error of the beta coefficient, \(n\) is the number of subjects and \(p\) the number of predictors.
if (!"visualize" %in% installed.packages()) {
install.packages("visualize")}
library("visualize")
# p-value for b0
visualize.t(c(-t.b0,t.b0),df.b0,section='tails')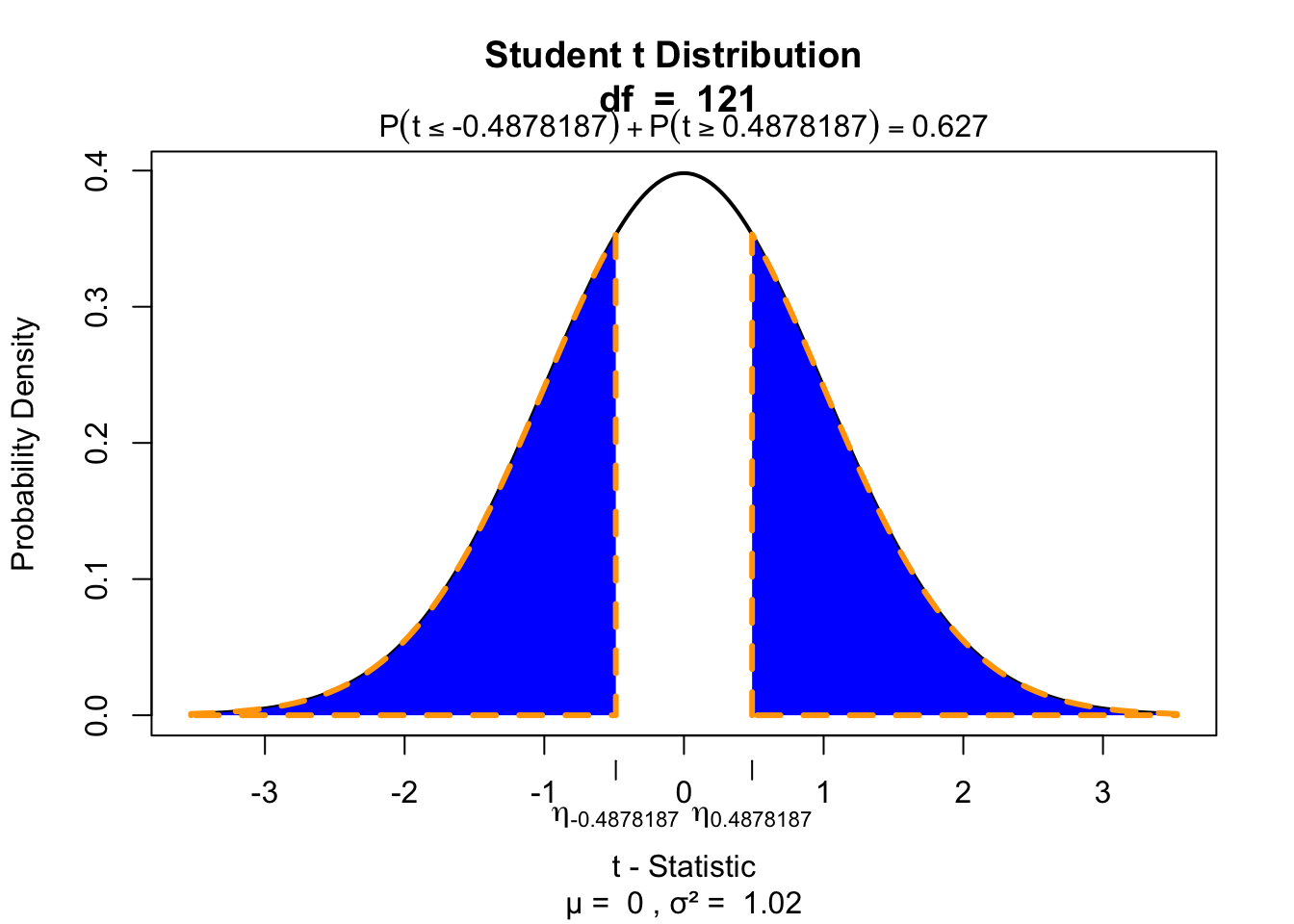
P-values of \(b_1\)
# p-value for b1
visualize.t(c(-t.b1,t.b1),df.b1,section='tails')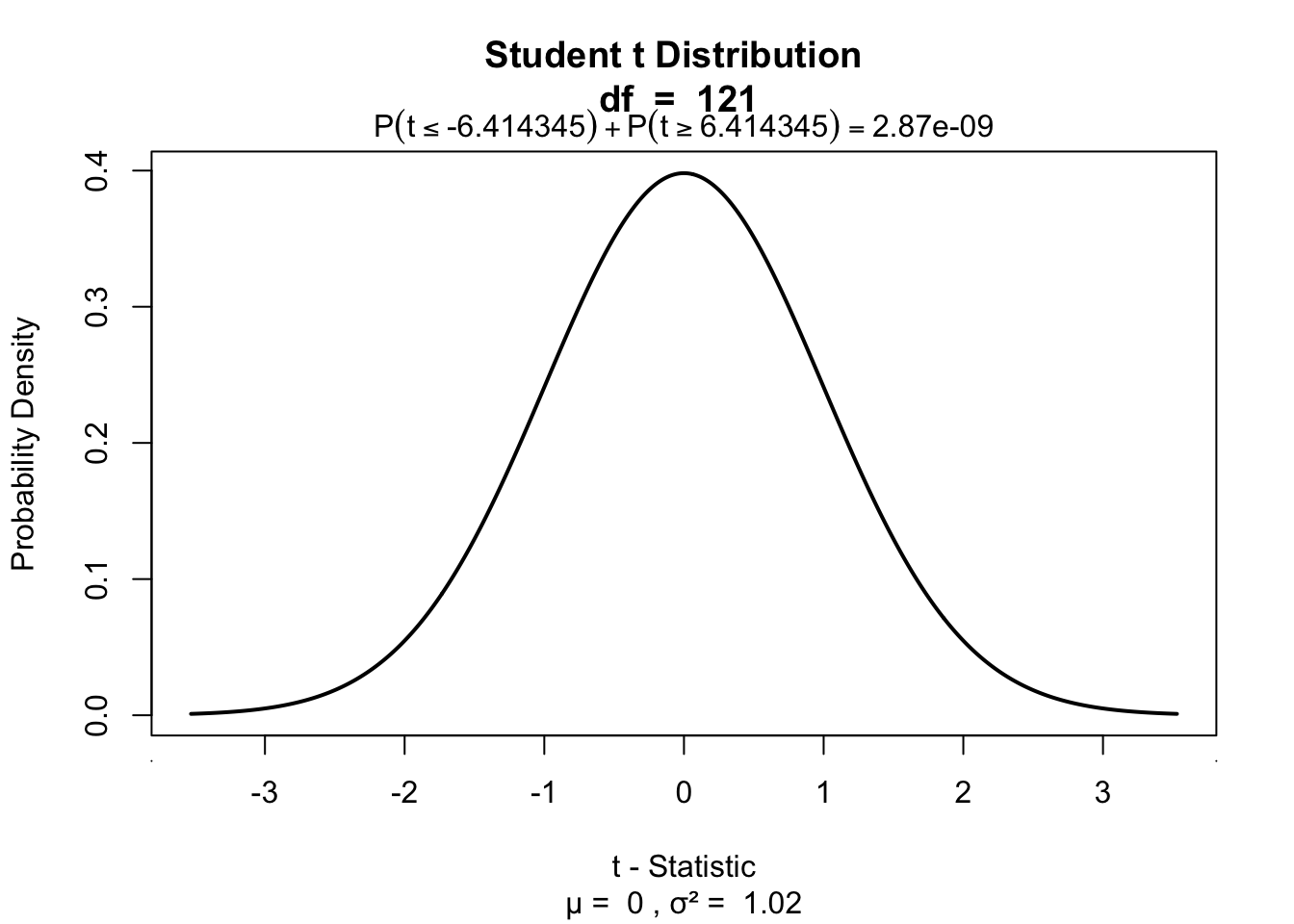
Define regression equation
\[\widehat{grade} = {model} = b_0 + b_1 {IQ}\]
So now we can add the expected grade based on this model
data$model = b0 + b1 * IQ
data$model <- round(data$model, 2)Expected values
Let’s have a look
\(y\) vs \(\hat{y}\)
And lets have a look at this relation between expectation and reality
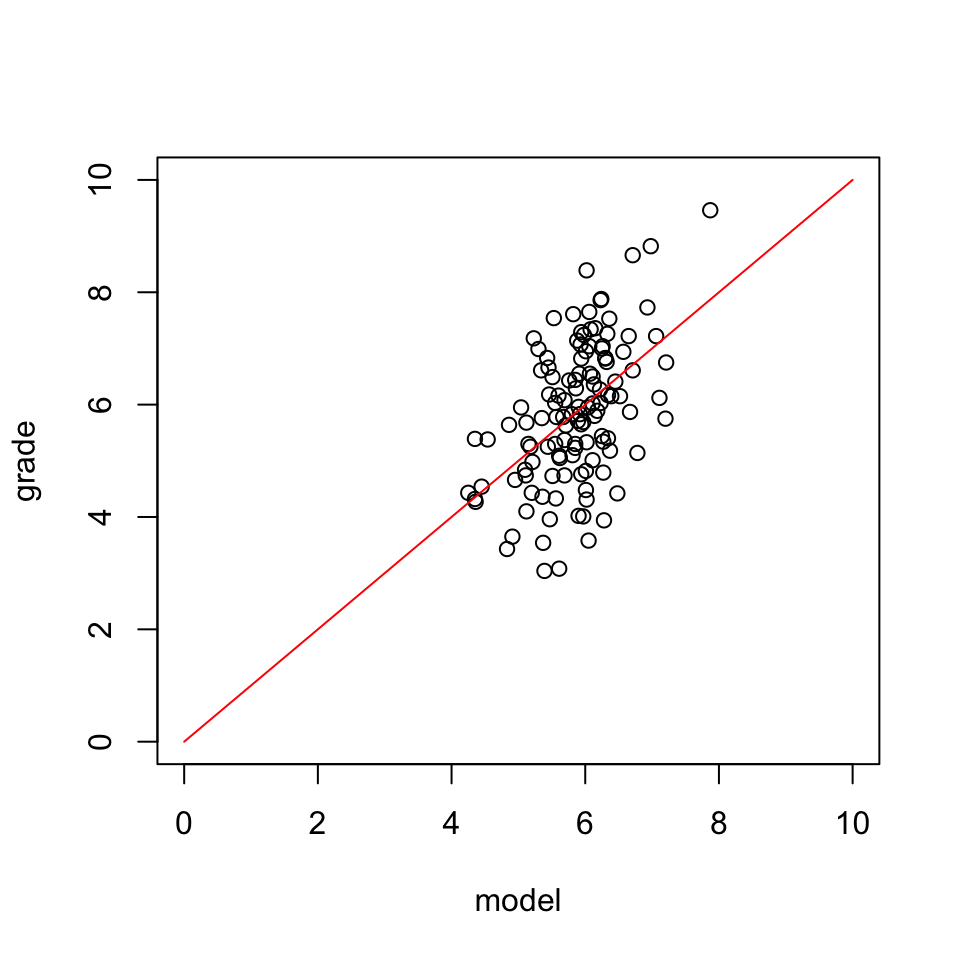
Error
The error / residual is the difference between the model expectation and reality
data$error = grade - model
data$error <- round(data$error, 2)Model fit
The fit of the model is the amount of error, which can be viewed in the correlation (\(r\)).
r = cor(model,grade)
r[1] 0.5035925Explained variance
r^2[1] 0.2536054Explained variance visually
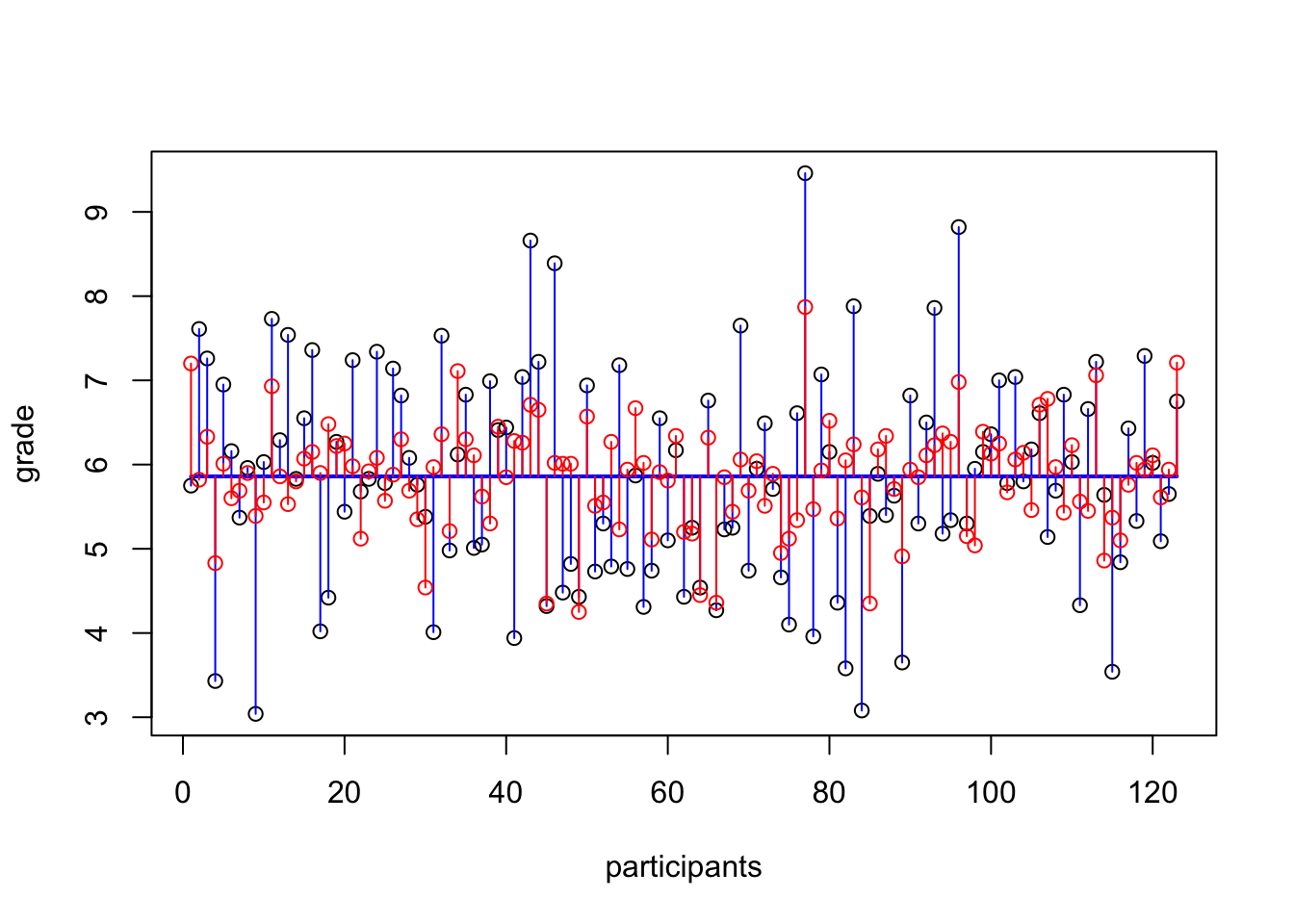
The part that does not overlap is therefore ‘unexplained’ variance. And because \(r^2\) is the explained variance, \(1 - r^2\) is the unexplained variance.
Test model fit
Compare model to mean Y (grade) as model
\[F = \frac{(n-p-1) r^2}{p (1-r^2)}\]
Where \({df}_{model} = n - p - 1 = N - K - 1\).
F = ( (n-p-1)*r^2 ) / ( p*(1-r^2) )
F[1] 41.11265Signal to noise
Given the description of explained variance, F can again be seen as a proportion of explained to unexplained variance. Also known as a signal to noise ratio.
df.model = p # n = rows, p = predictors
df.error = n-p-1
SS_model = sum((model - mean(grade))^2)
SS_error = sum((grade - model)^2)
MS_model = SS_model / df.model
MS_error = SS_error / df.error
F = MS_model / MS_error
F[1] 41.1269SS_total = var(grade) * (n-1)
rbind(SS_total,
SS_model,
# Proportion explained variance
SS_model / SS_total,
r^2) [,1]
SS_total 191.0732000
SS_model 48.4740000
0.2536933
0.2536054Visualize
visualize.f(F, df.model, df.error, section='upper')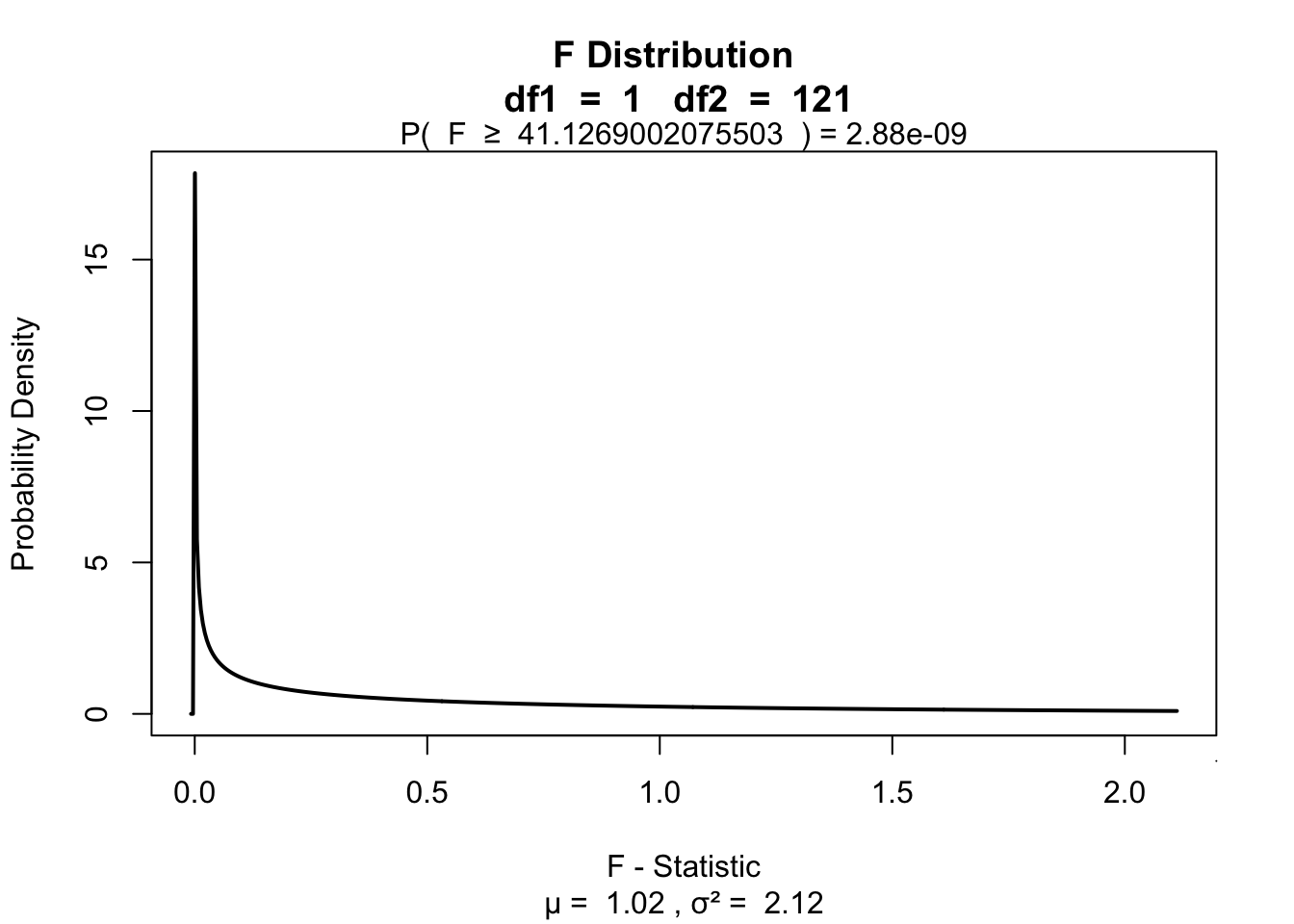
End
Contact
