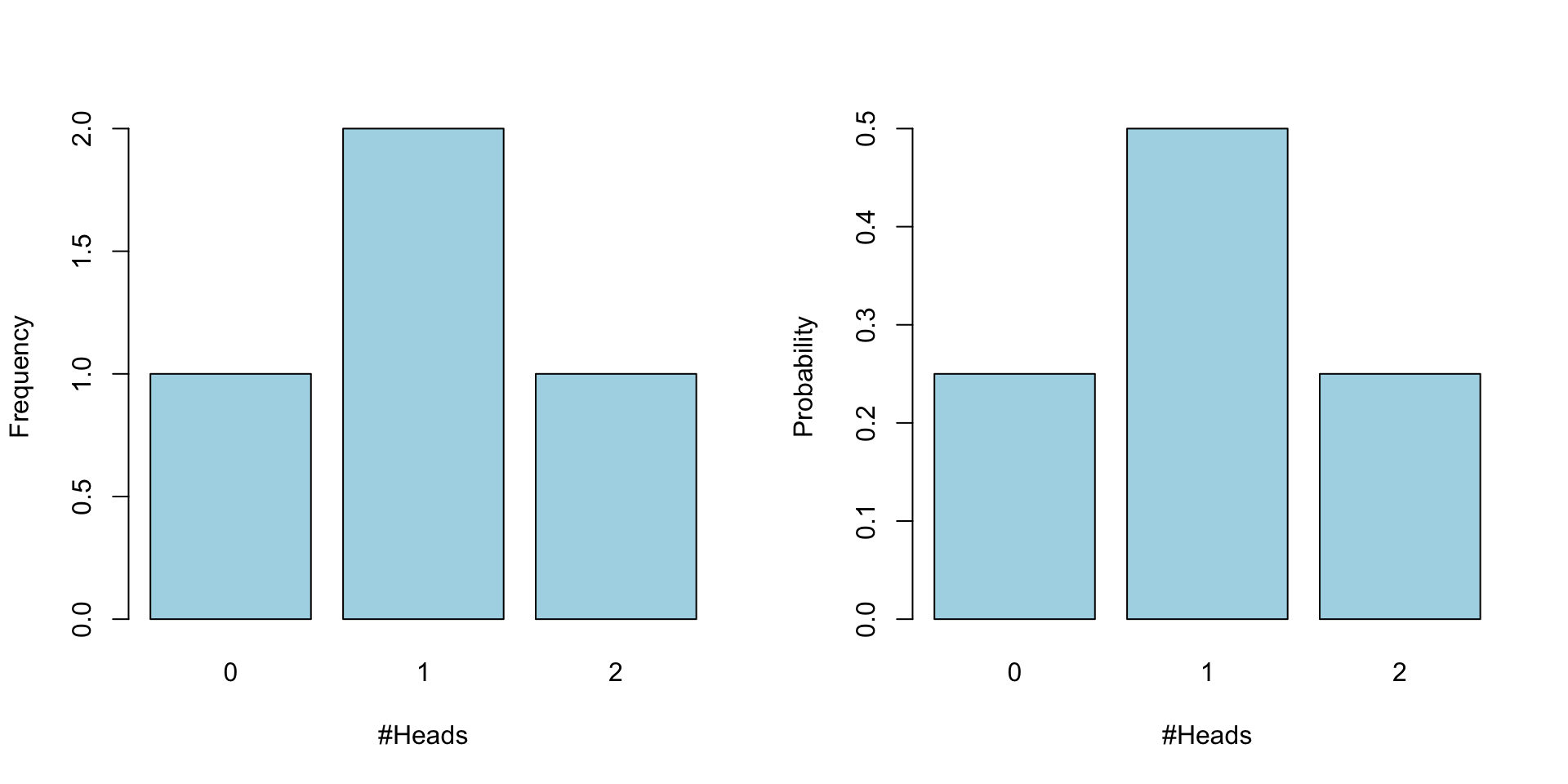
Toss1 Toss2
1 0 0
2 1 0
3 0 1
4 1 1Probability Models
2024-09-09
Frequecy and probability distribution
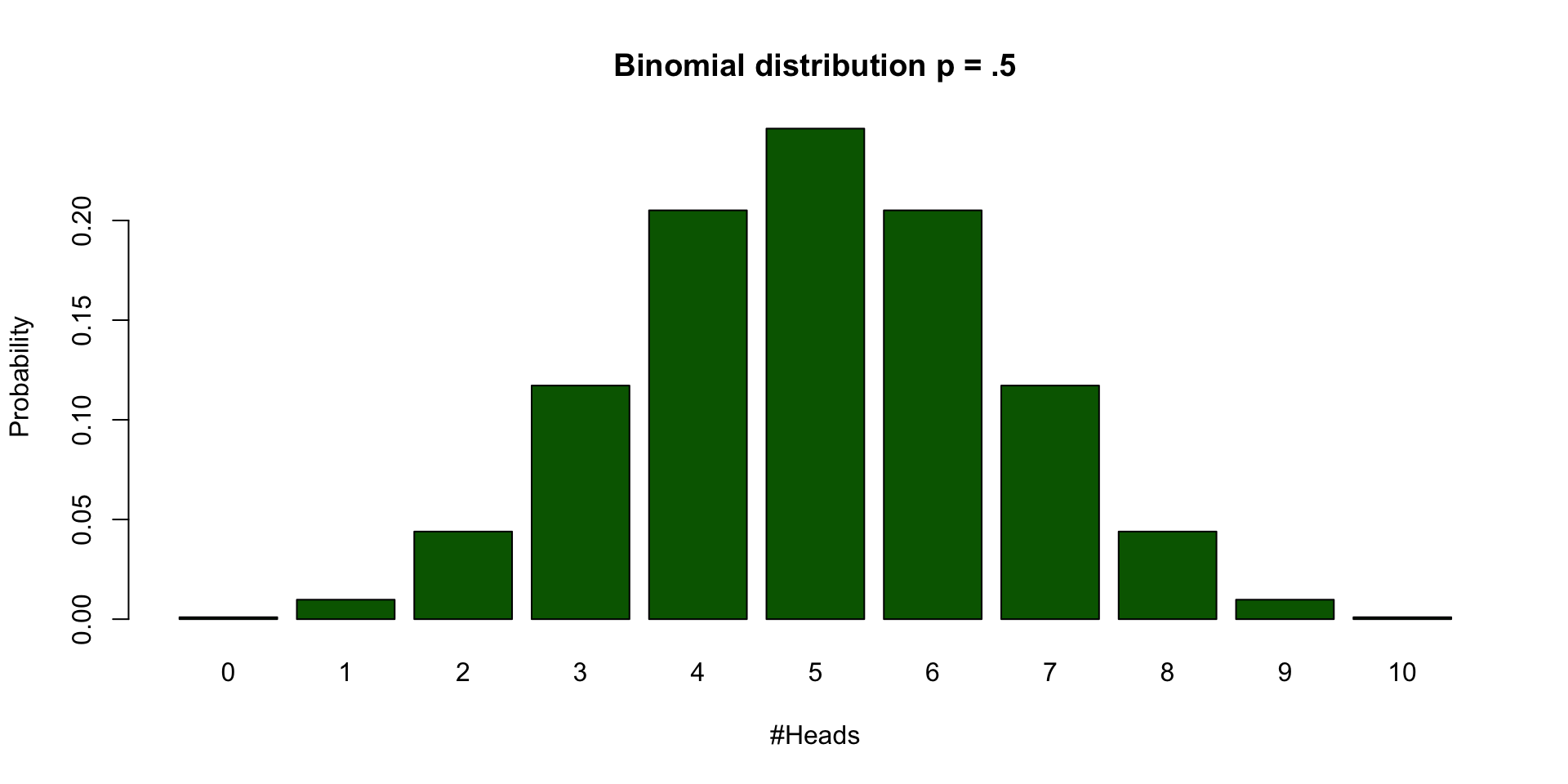
Binomial distribution
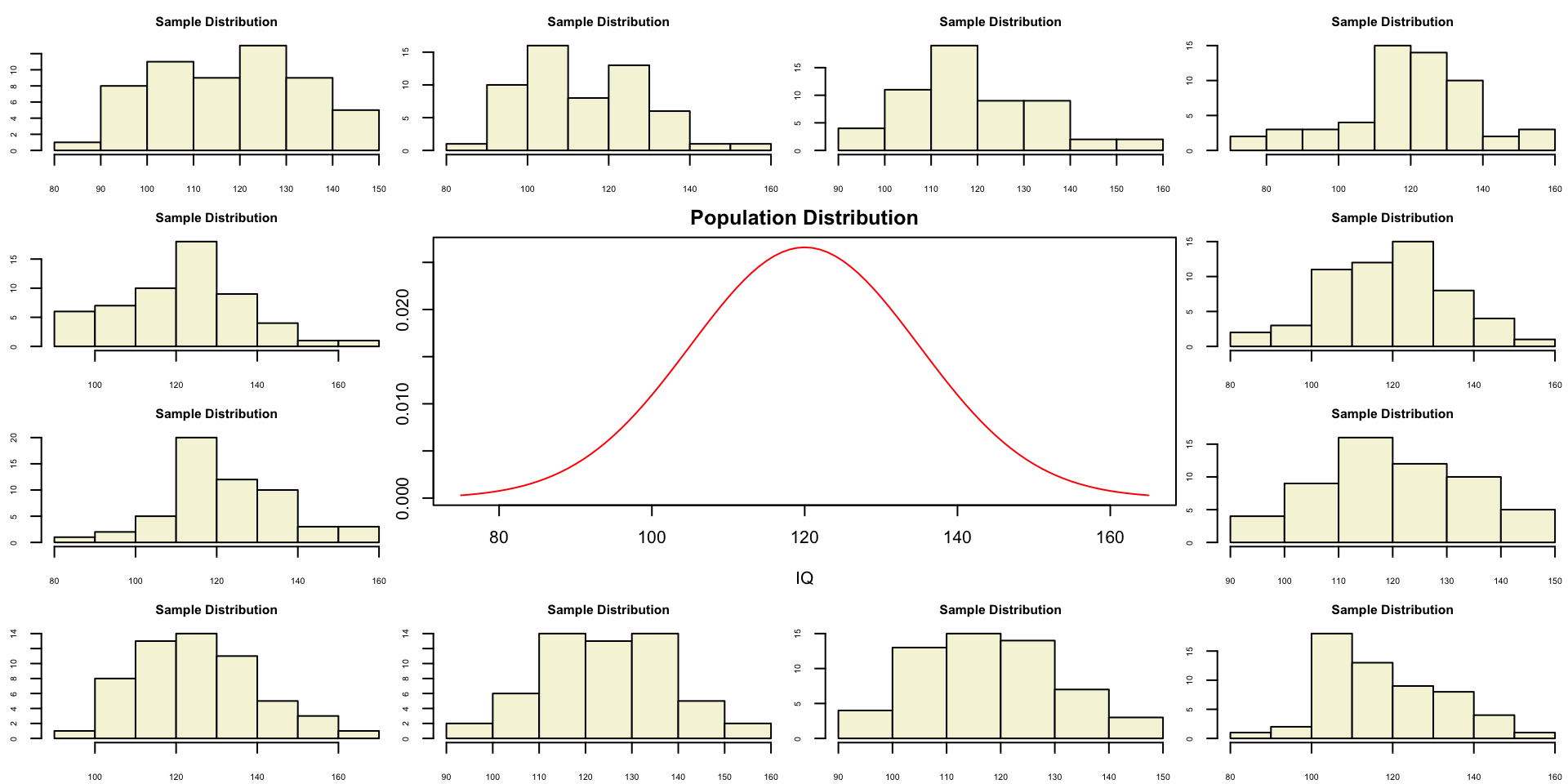
Bootstrapped sampling distribution

Continuous Probability distirbutions

For all continuous probability distributions:
- Total area is always 1
- The probability of one specific test statistic is 0
- x-axis represents the test statistic
- y-axis represents the probability density
Gosset

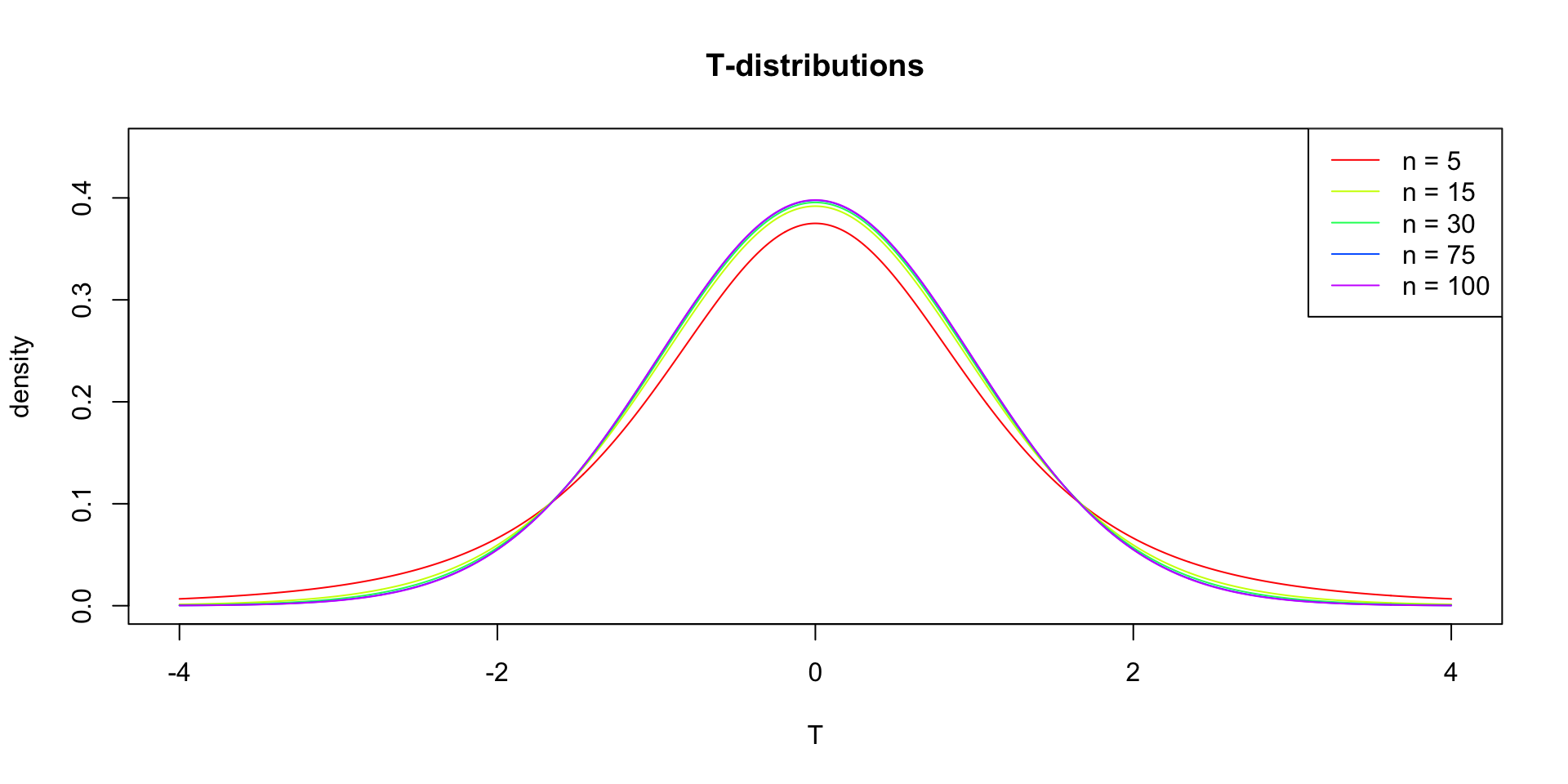
In probability and statistics, Student’s t-distribution (or simply the t-distribution) is any member of a family of continuous probability distributions that arises when estimating the mean of a normally distributed population in situations where the sample size is small and population standard deviation is unknown.
In the English-language literature it takes its name from William Sealy Gosset’s 1908 paper in Biometrika under the pseudonym “Student”. Gosset worked at the Guinness Brewery in Dublin, Ireland, and was interested in the problems of small samples, for example the chemical properties of barley where sample sizes might be as low as 3 (Wikipedia, 2024).
Population distribution
One sample
Let’s take a larger sample from our normal population.
[1] 139.83142 120.80322 100.62919 102.66002 116.51932 115.19516 110.53936
[8] 107.51484 102.55489 74.64233 122.80955 104.21127 136.58620 149.09940
[15] 130.07008 97.55550 145.03904 116.53760 140.85901 126.10327 118.31334
[22] 129.12780 105.23544 106.73443 127.15296 120.59382 107.67602 133.55126
[29] 96.98829 131.76937 106.14565 132.41319 110.97578 109.97020 115.70138
[36] 109.01660 123.37200 129.47526 123.61422 132.80877 108.97379 135.99577
[43] 117.41297 111.84105 112.74894 107.11346 119.83987 147.38322 123.29201
[50] 113.21733 113.69499 126.80494 109.80953 125.11899 125.11725 125.32108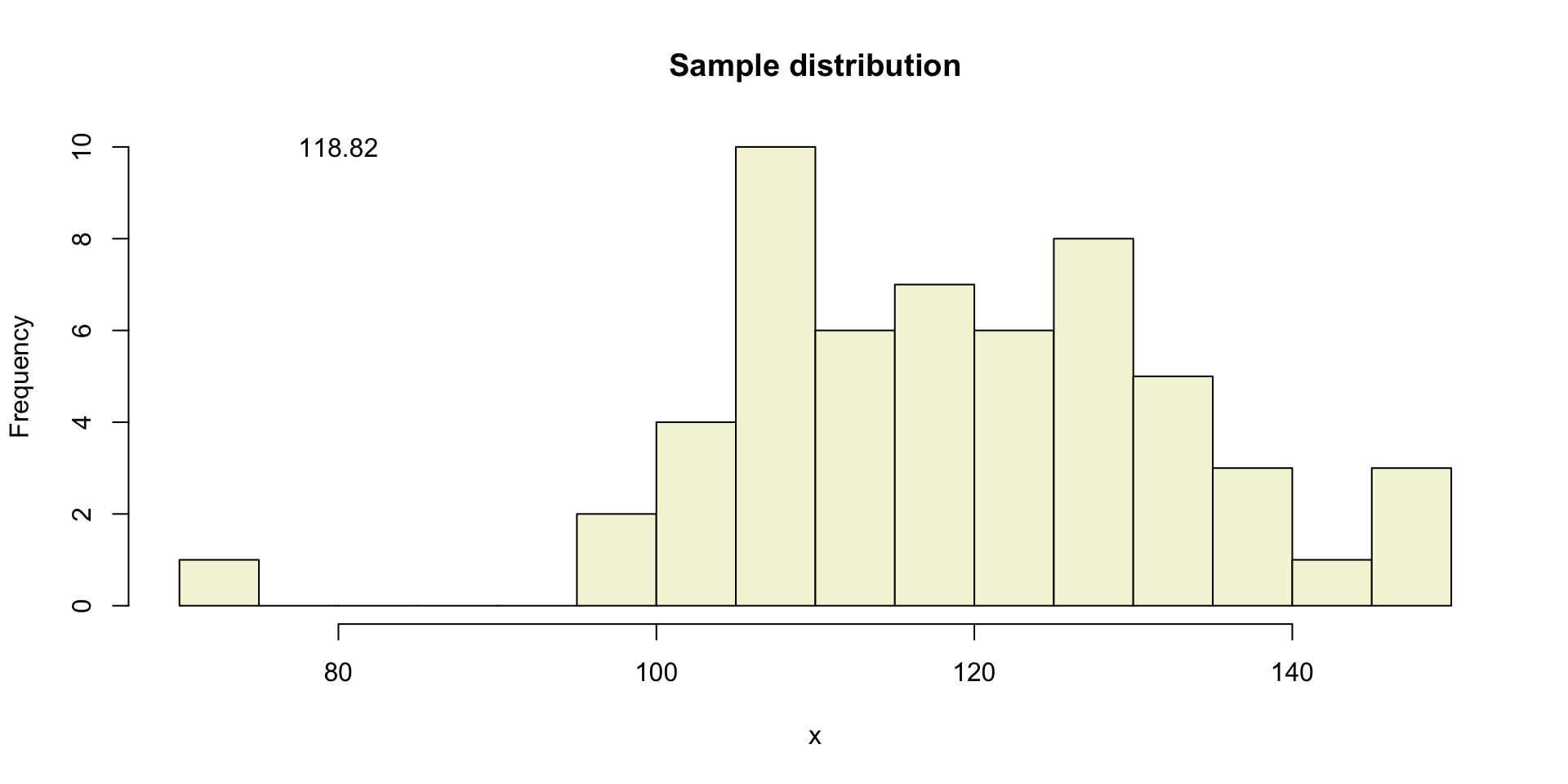
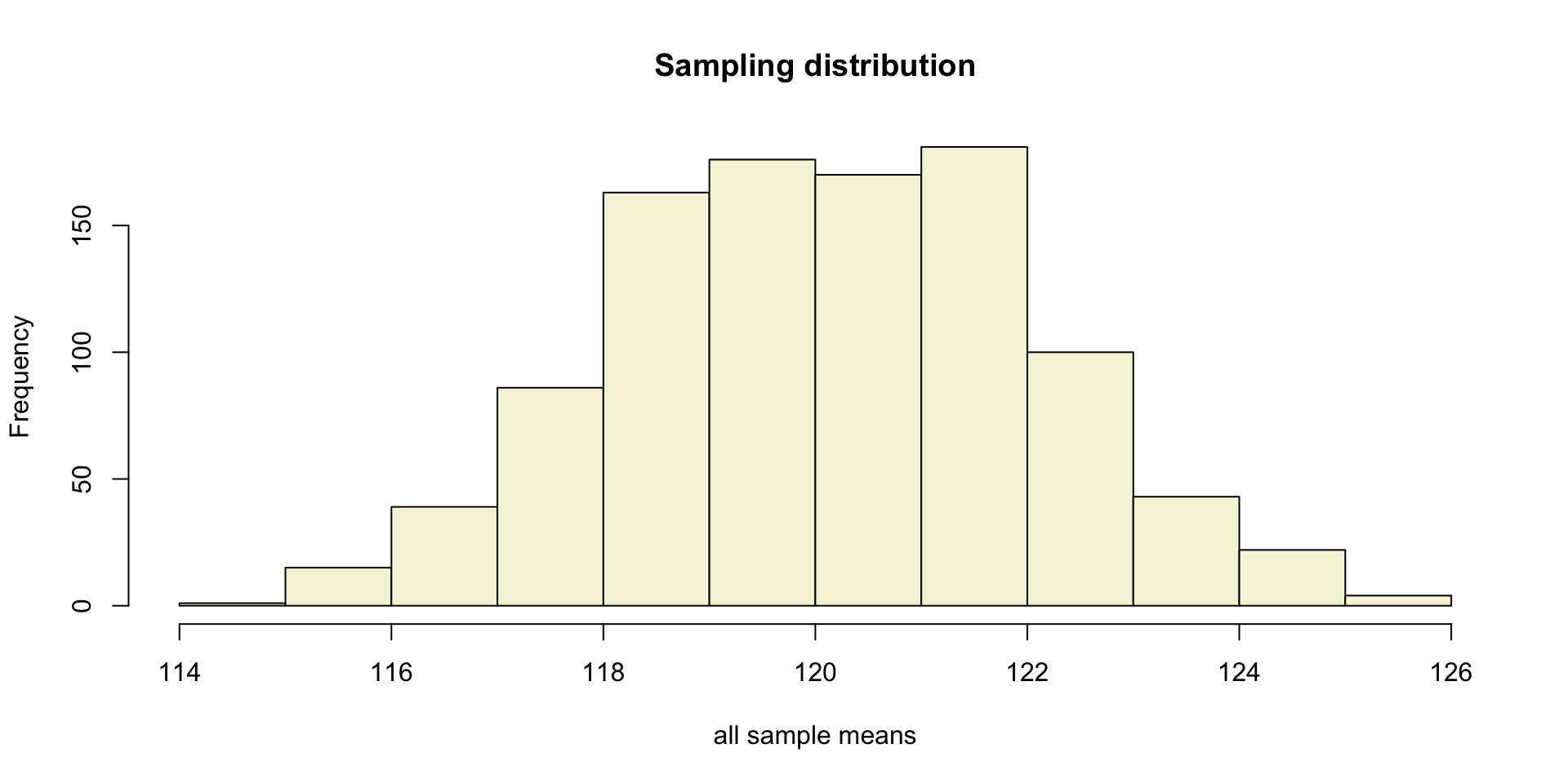
Sampling distribution
of the mean
Sampling distribution t-values

The t-distribution approximates the sampling distribution, hence the name theoretical approximation.
Contact

References
Wikipedia. (2024). Student’s t-distribution — Wikipedia, the free encyclopedia. http://en.wikipedia.org/w/index.php?title=Student's%20t-distribution&oldid=1202978121.
- Distribution illustration generated with DALL-E by OpenAI
![]()