F-Distribution and factorial ANOVA
9/25/23
Ronald Fisher
The F-distribution, also known as Snedecor’s F distribution or the Fisher–Snedecor distribution (after Ronald Fisher and George W. Snedecor) is, in probability theory and statistics, a continuous probability distribution. The F-distribution arises frequently as the null distribution of a test statistic, most notably in the analysis of variance; see F-test.
Sir Ronald Aylmer Fisher FRS (17 February 1890 – 29 July 1962), known as R.A. Fisher, was an English statistician, evolutionary biologist, mathematician, geneticist, and eugenicist. Fisher is known as one of the three principal founders of population genetics, creating a mathematical and statistical basis for biology and uniting natural selection with Mendelian genetics.

Population distribution
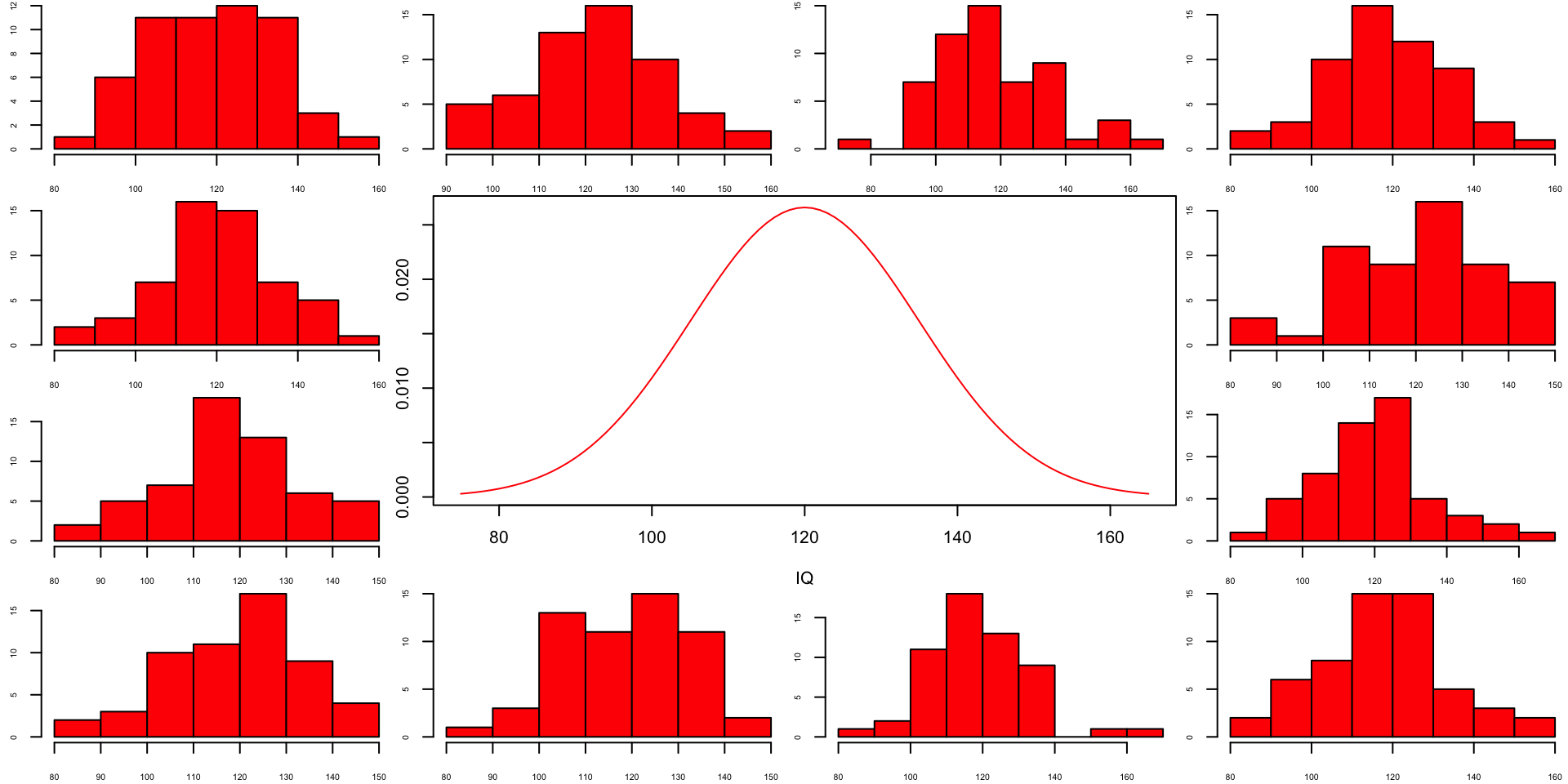
More samples
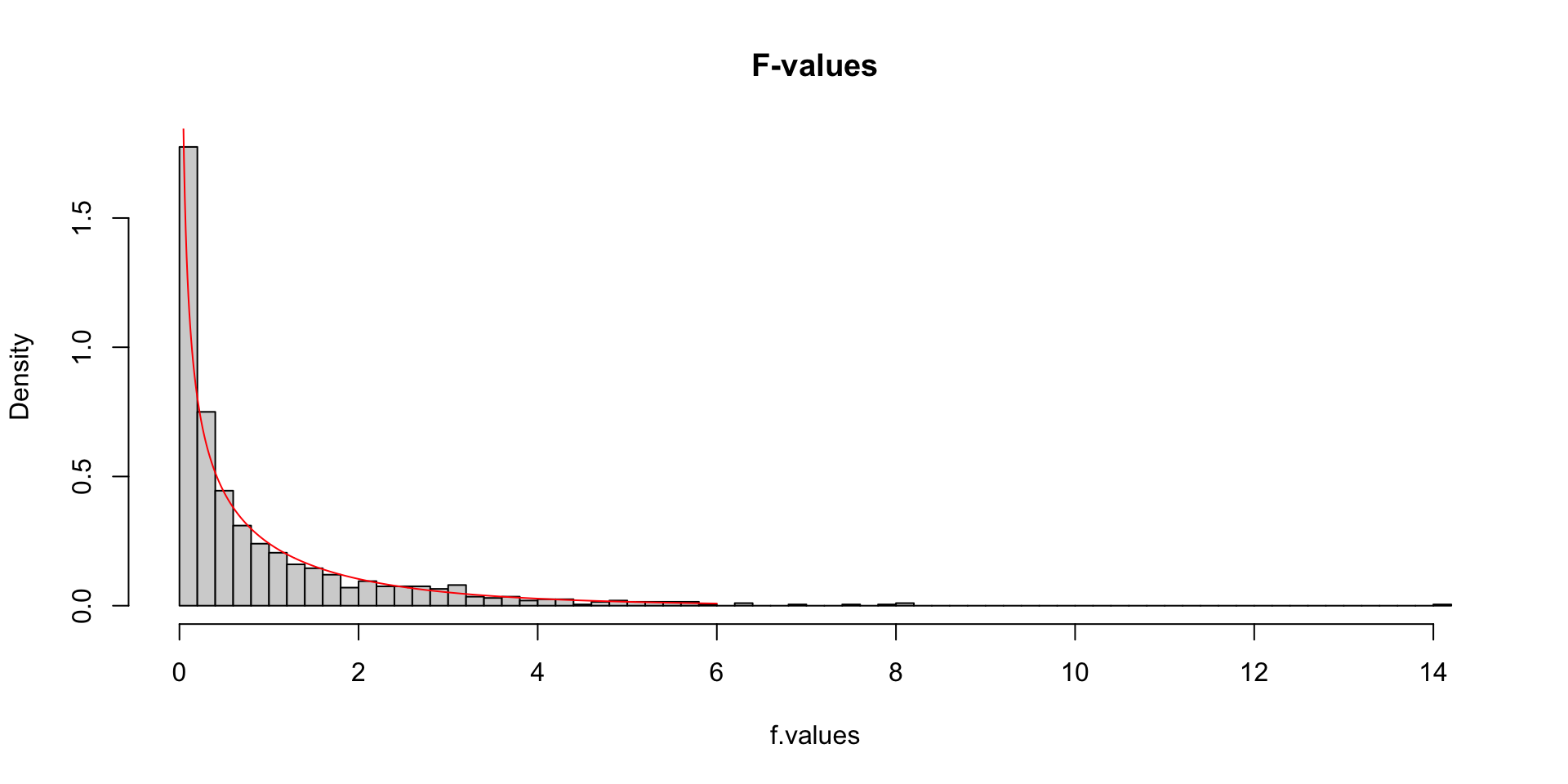
F-distribution
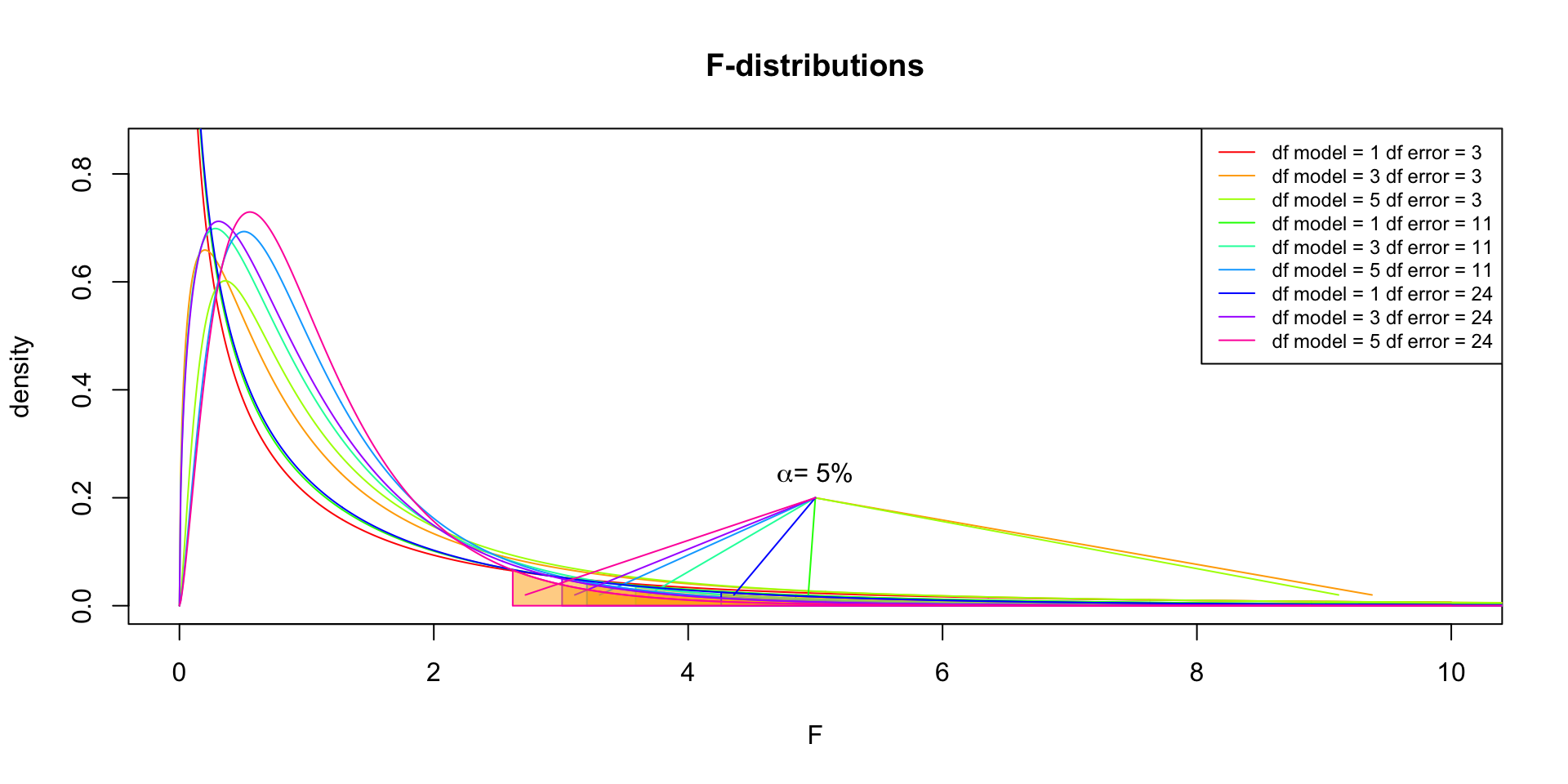
F-distribution
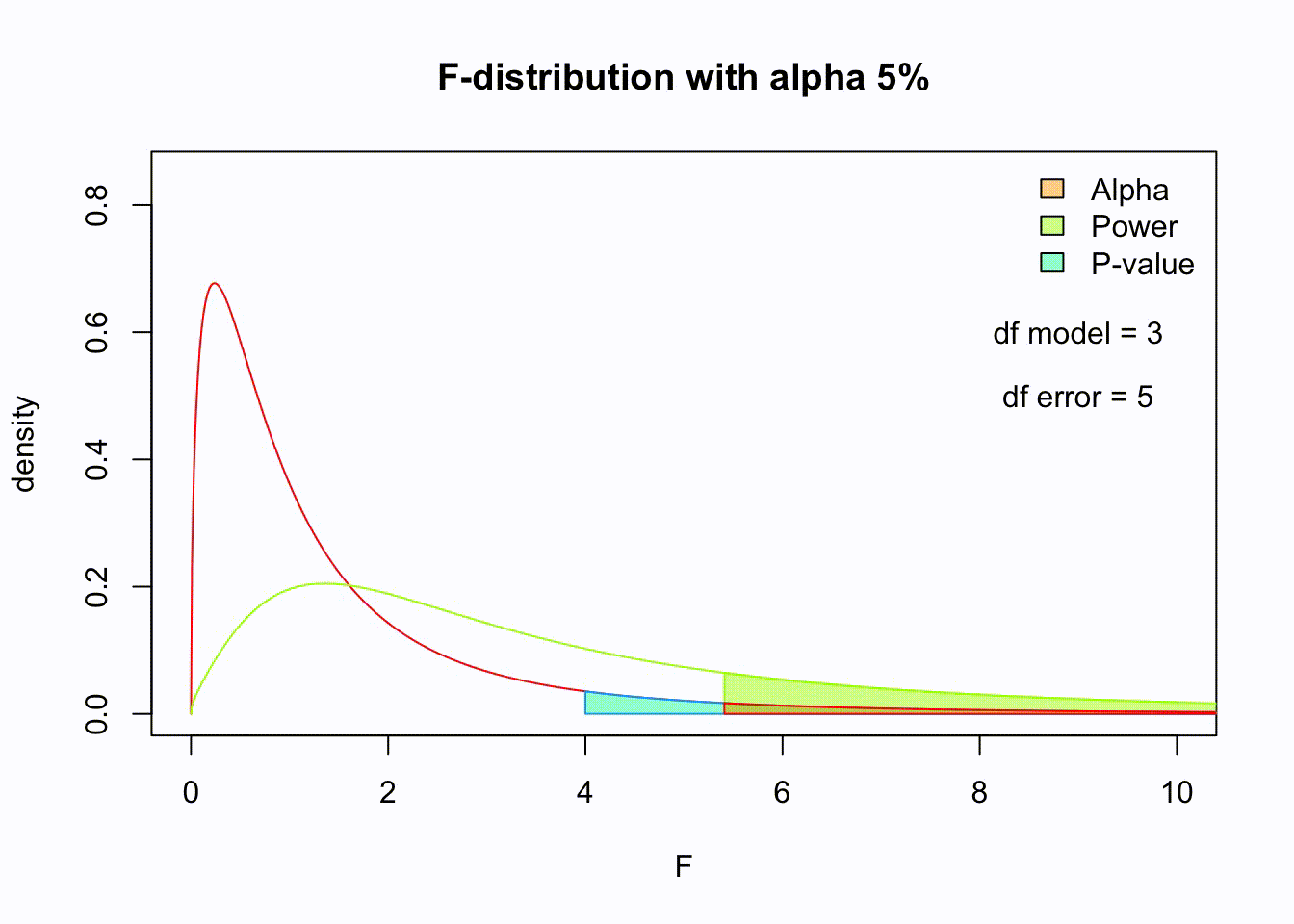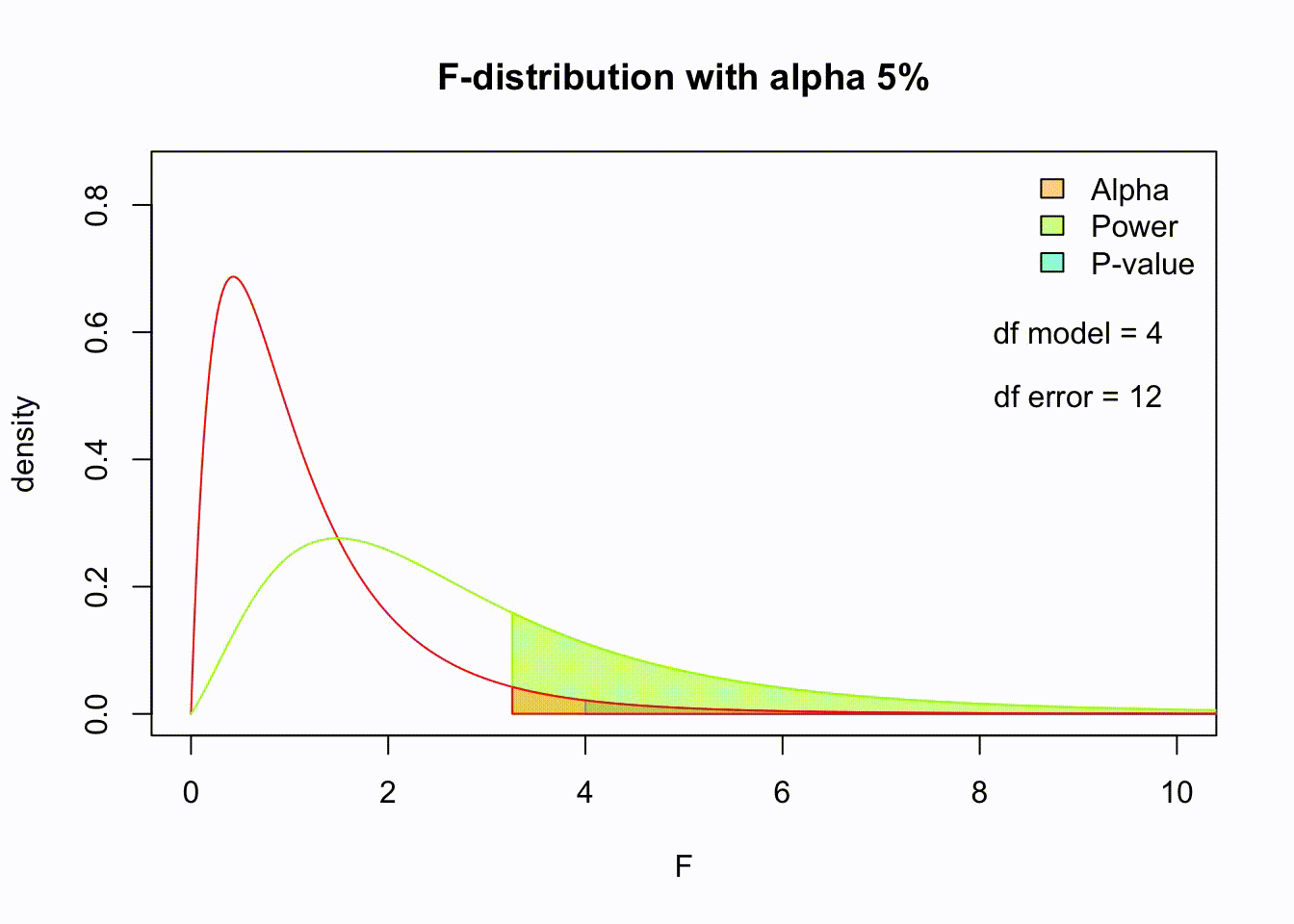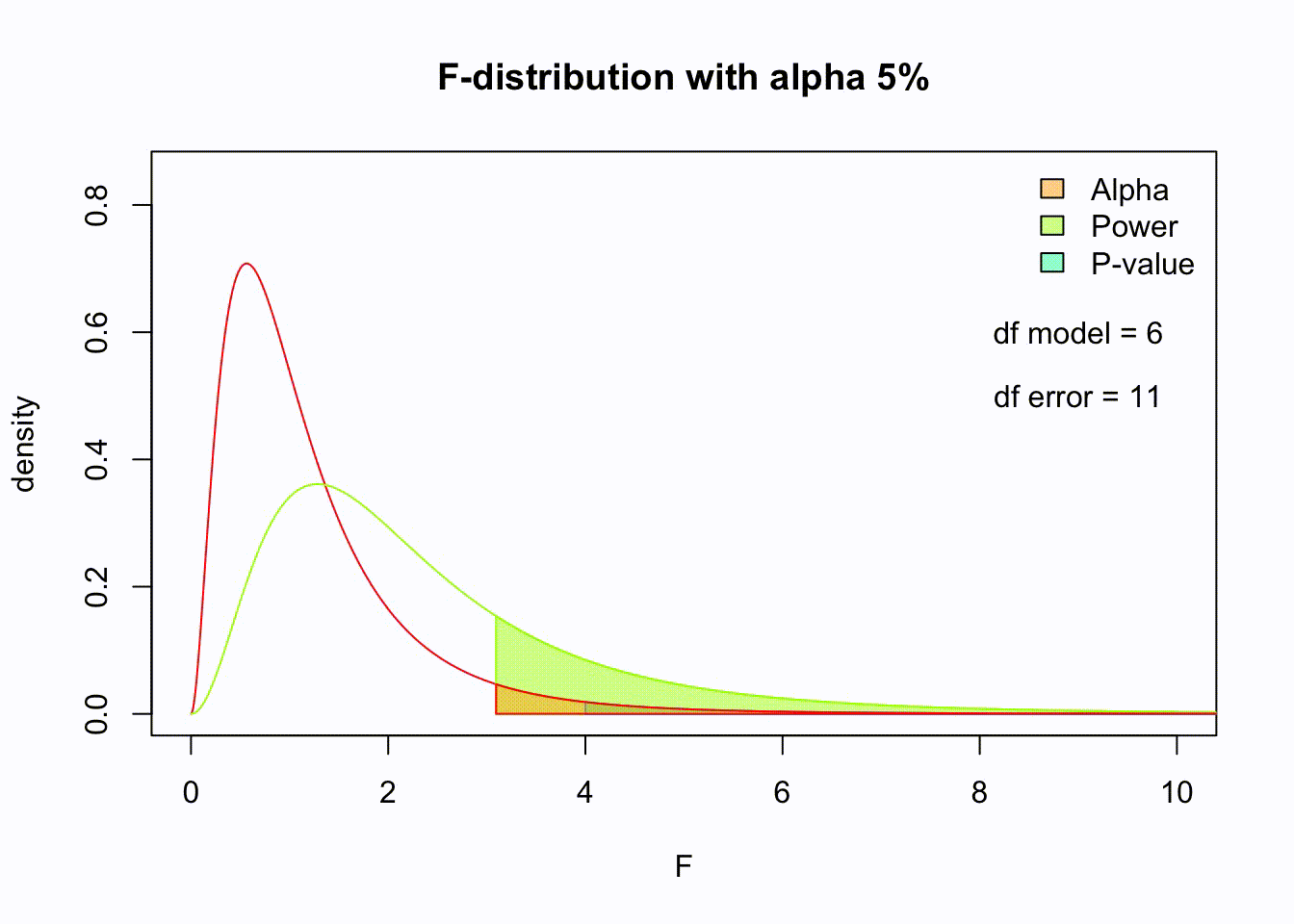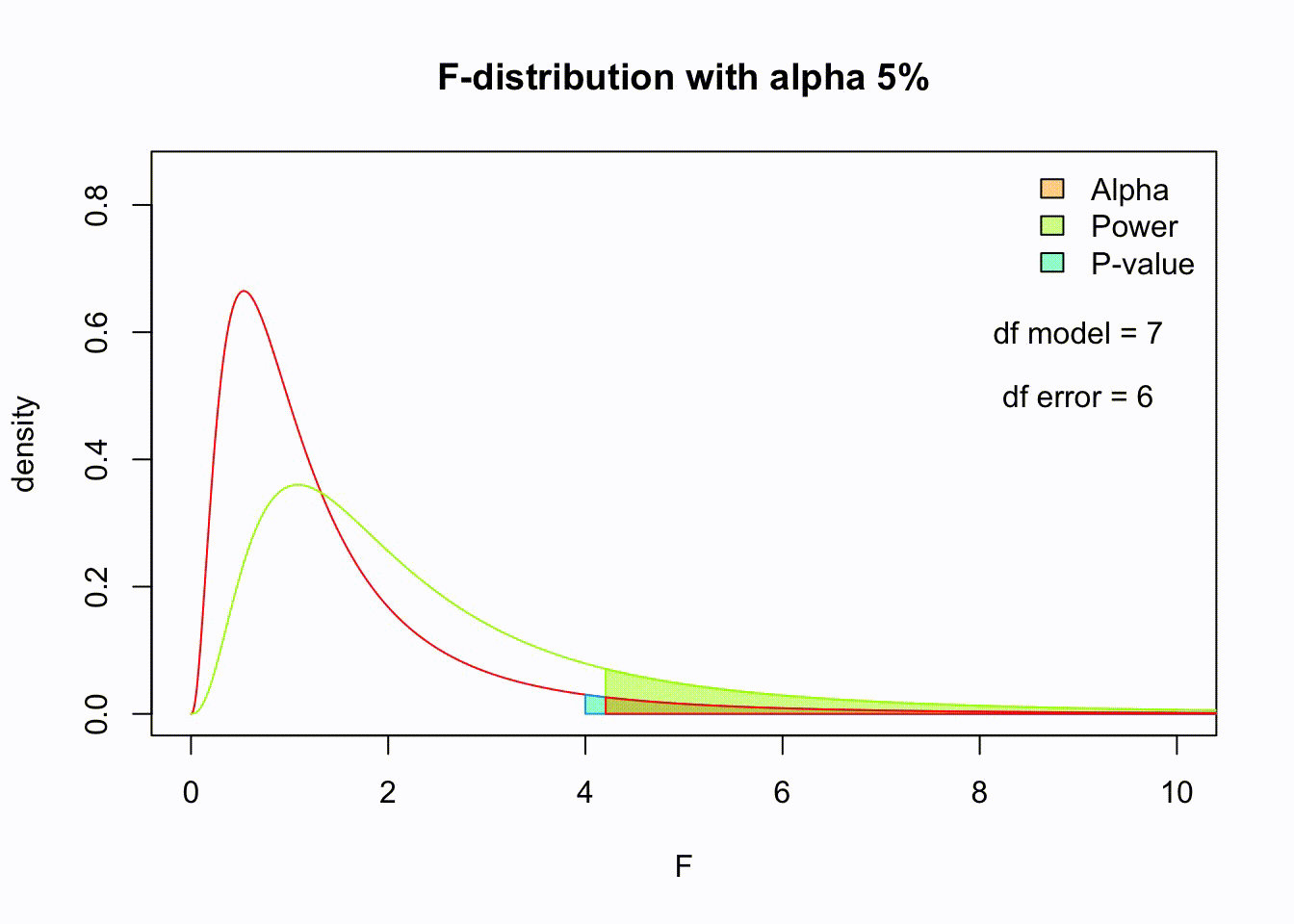
Animated F-distrigutions
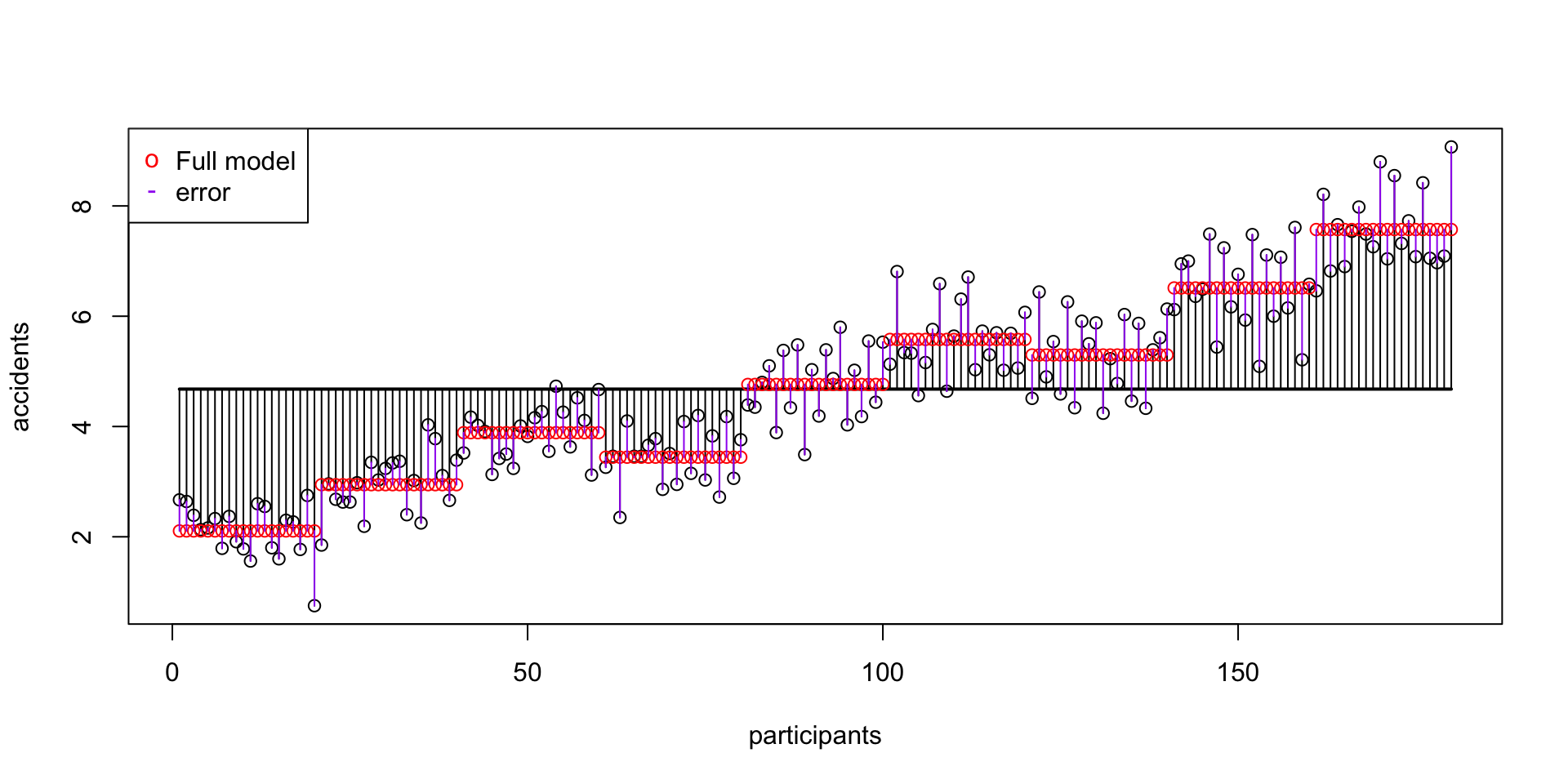
SS model
\(\text{SS}_\text{model} = 494.22048\)
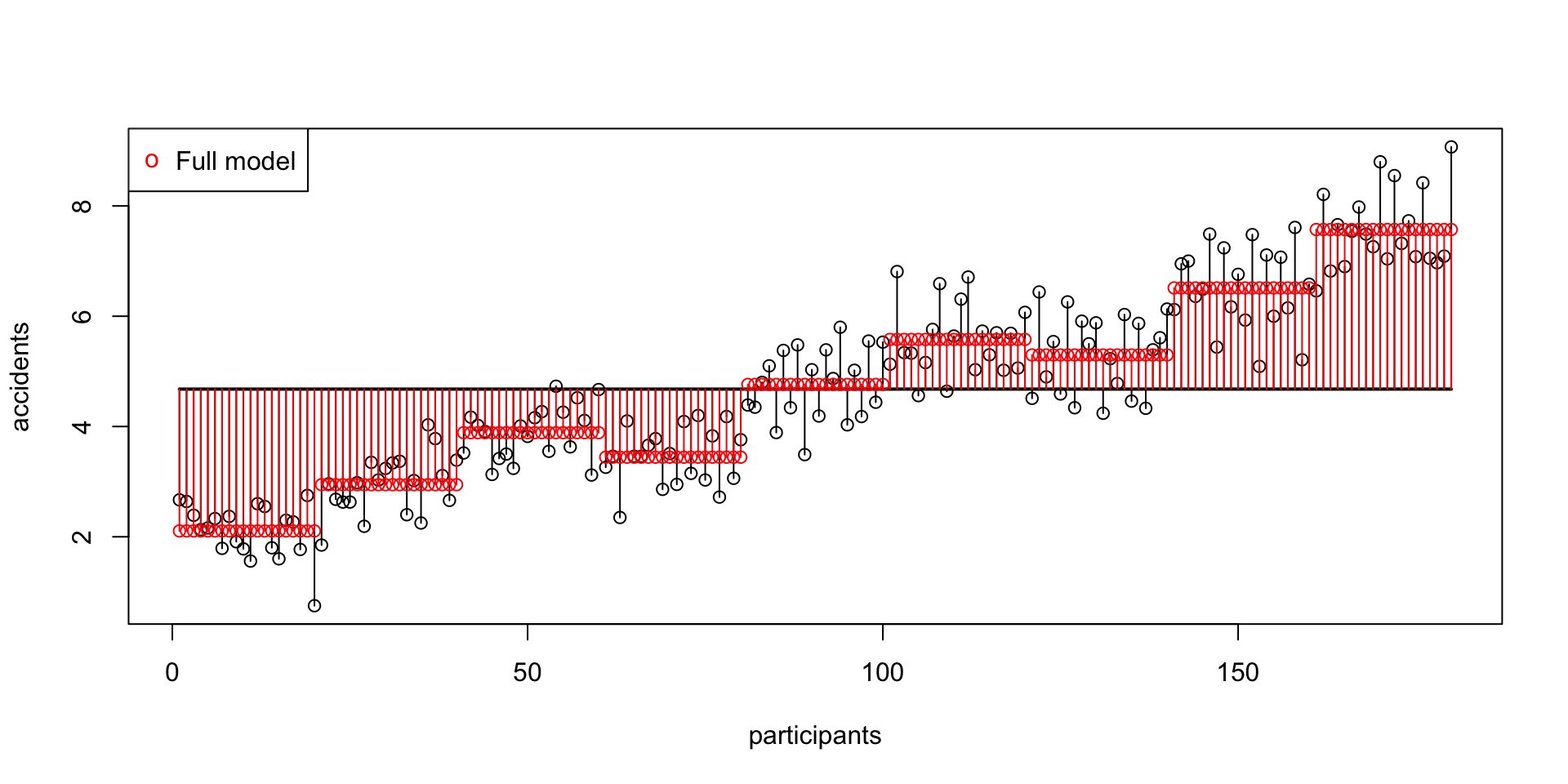
SS error
\(\text{SS}_\text{error} = 66.34642\)
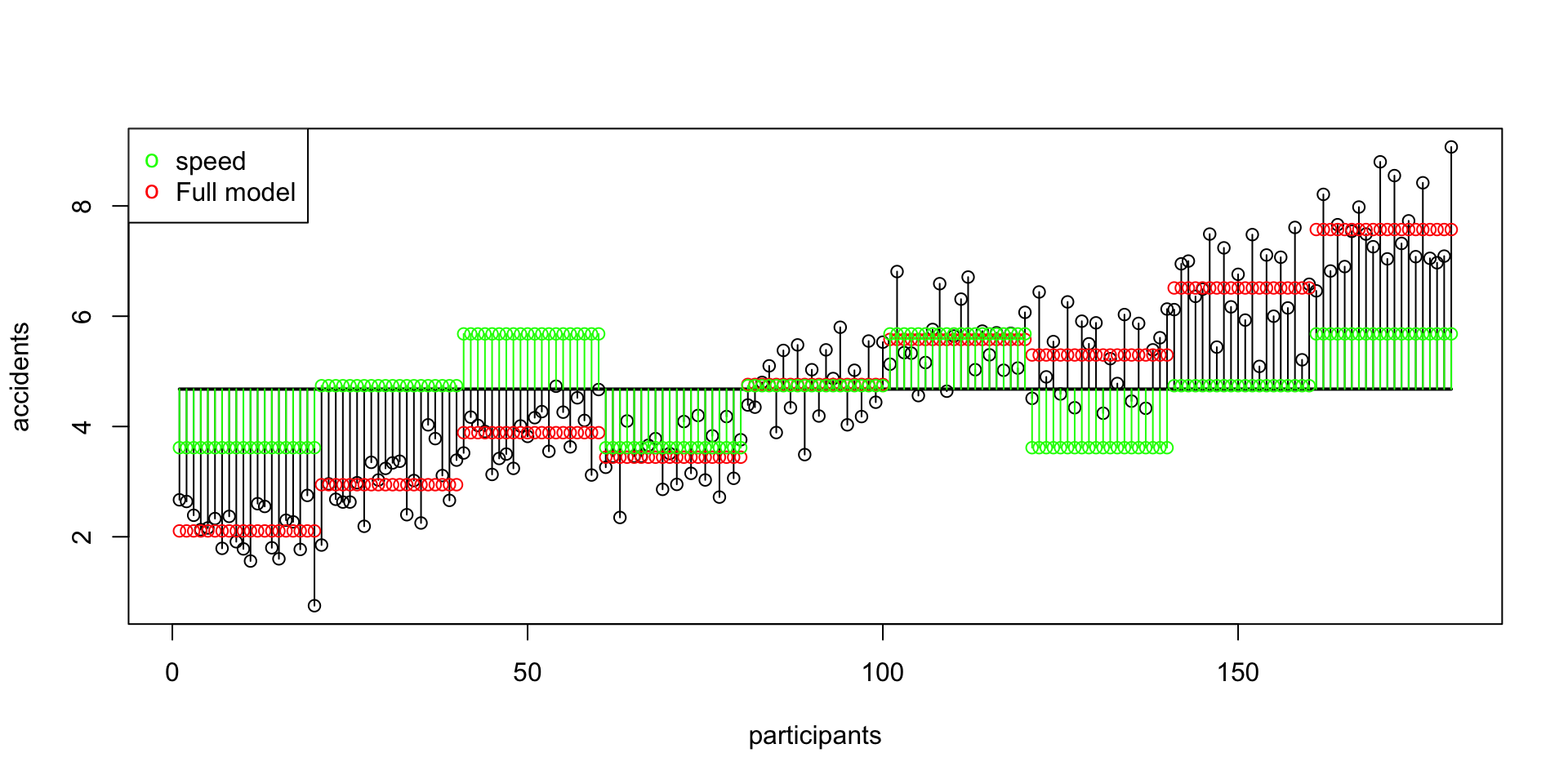
SS A Speed
\(\text{SS}_\text{speed} = 128.1639233\)
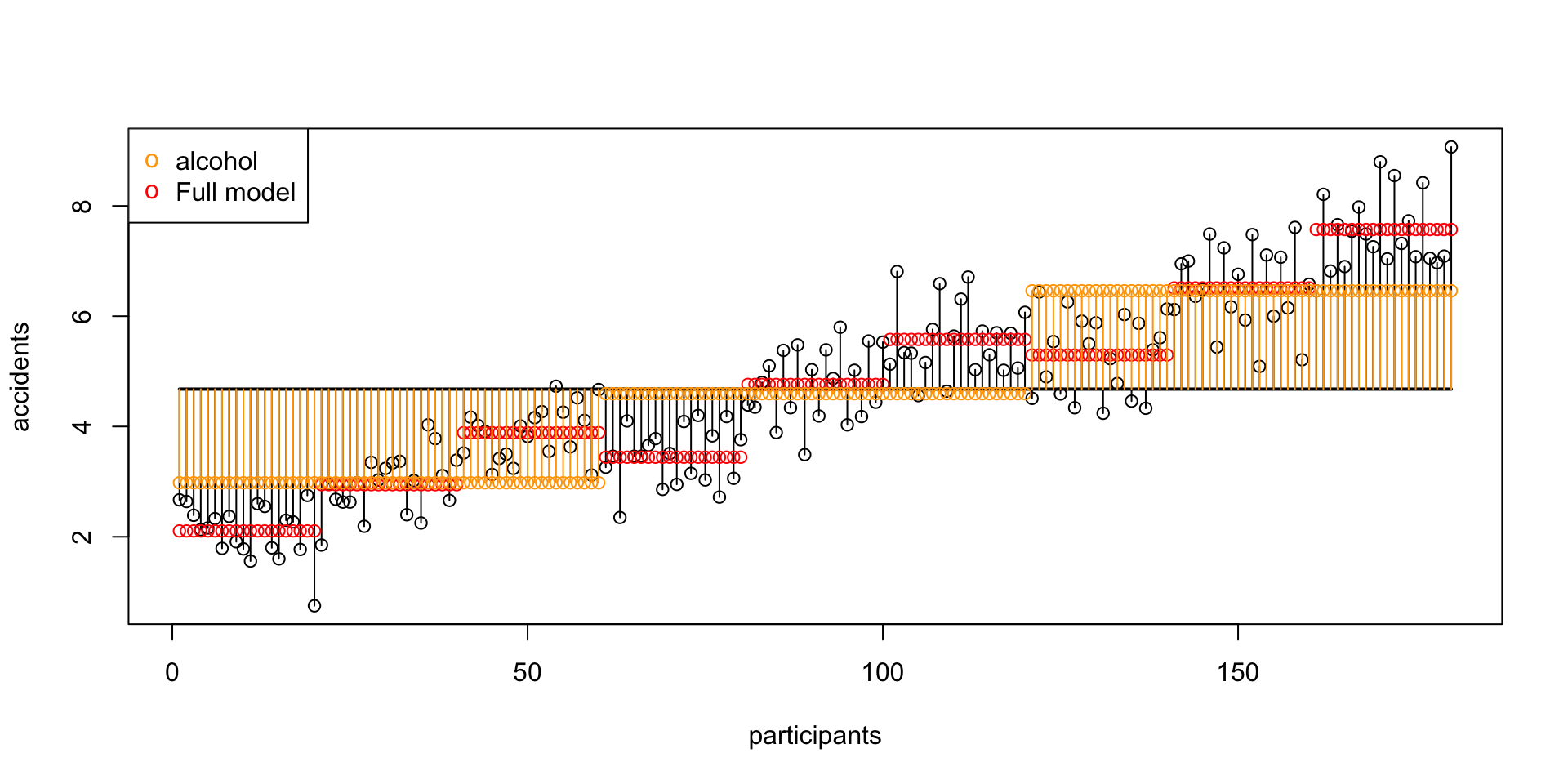
SS B Alcohol
\(\text{SS}_\text{alcohol} = 364.14583\)
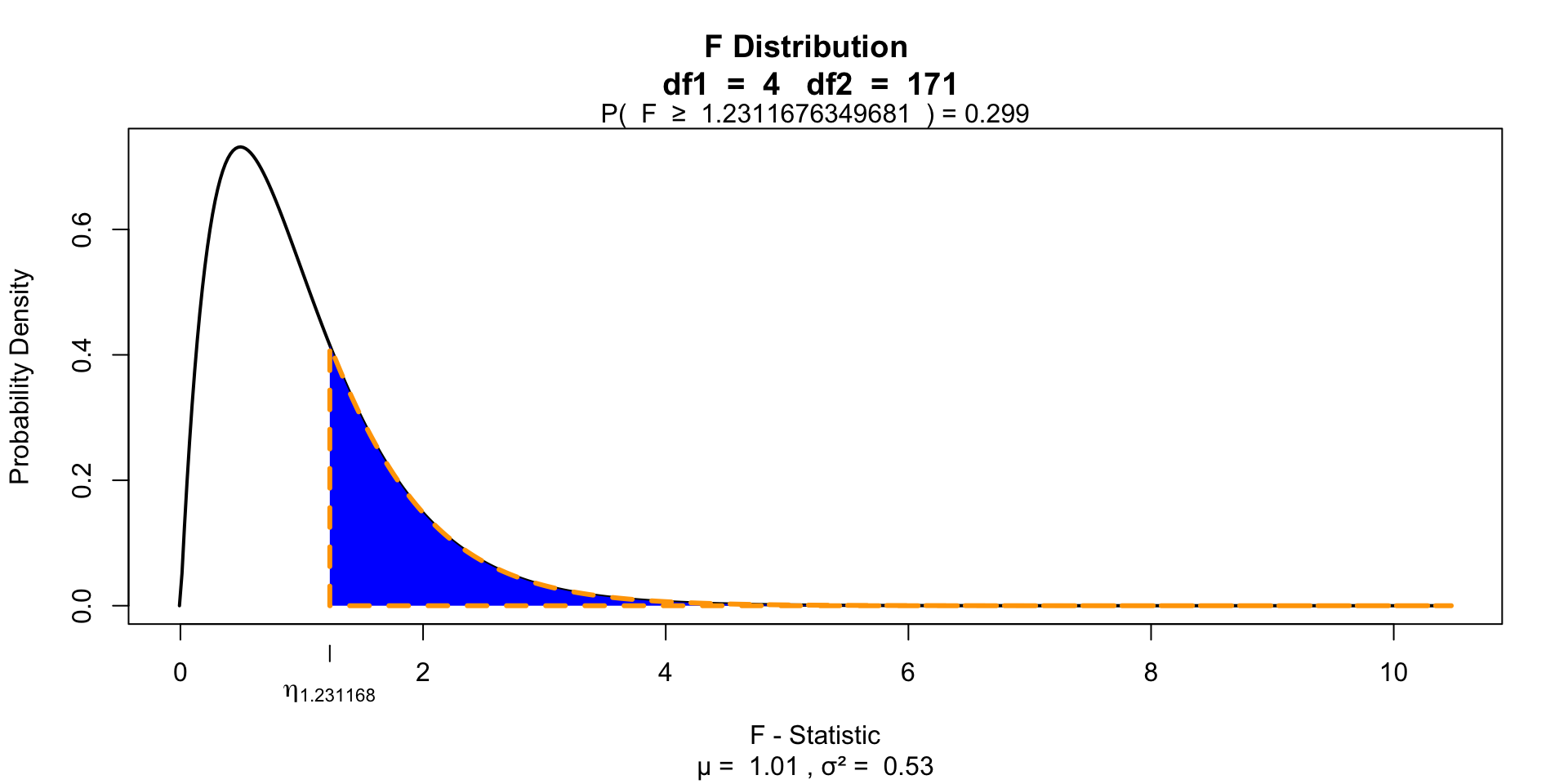
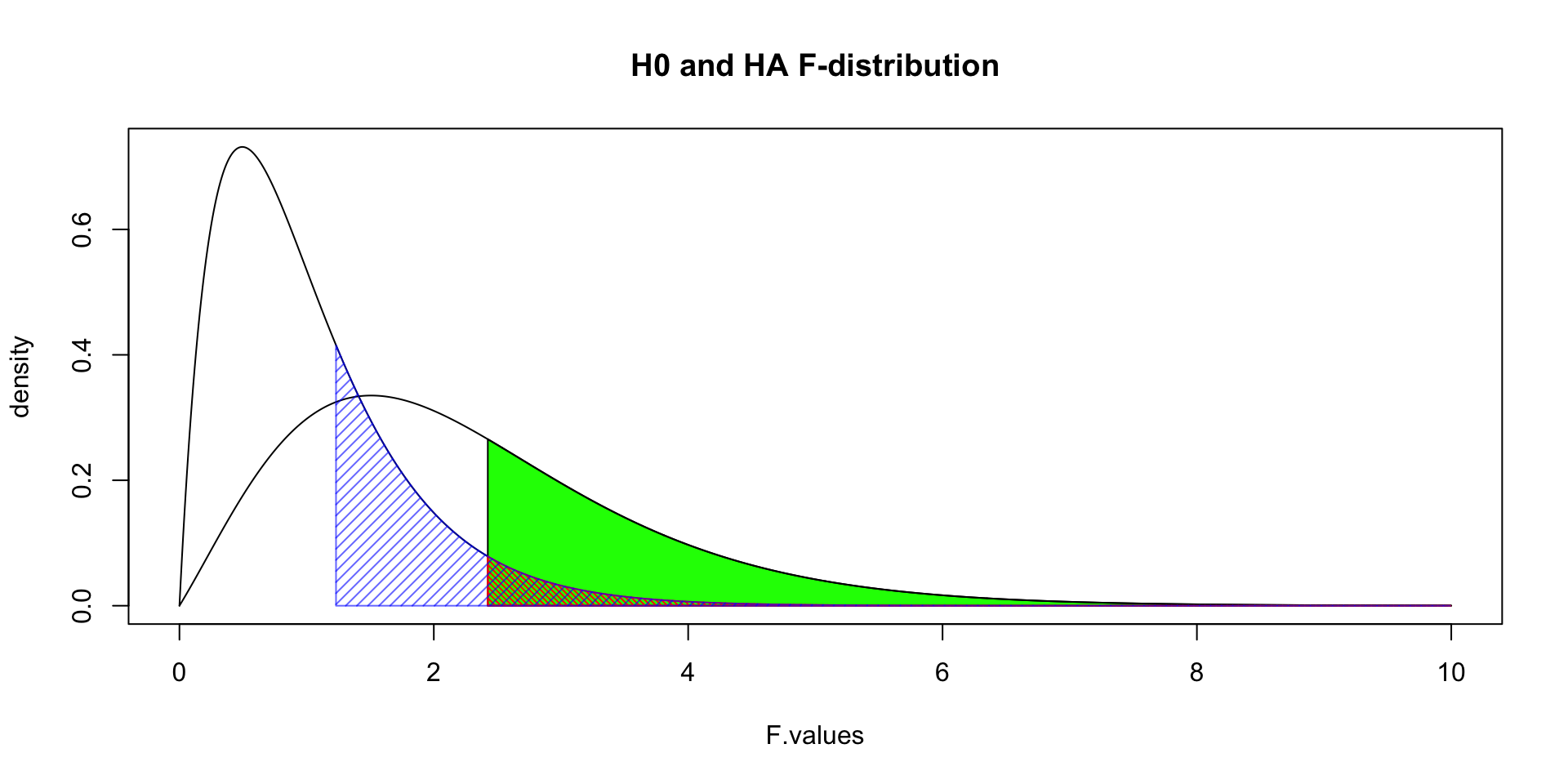
\(P\)-value
How good is the model
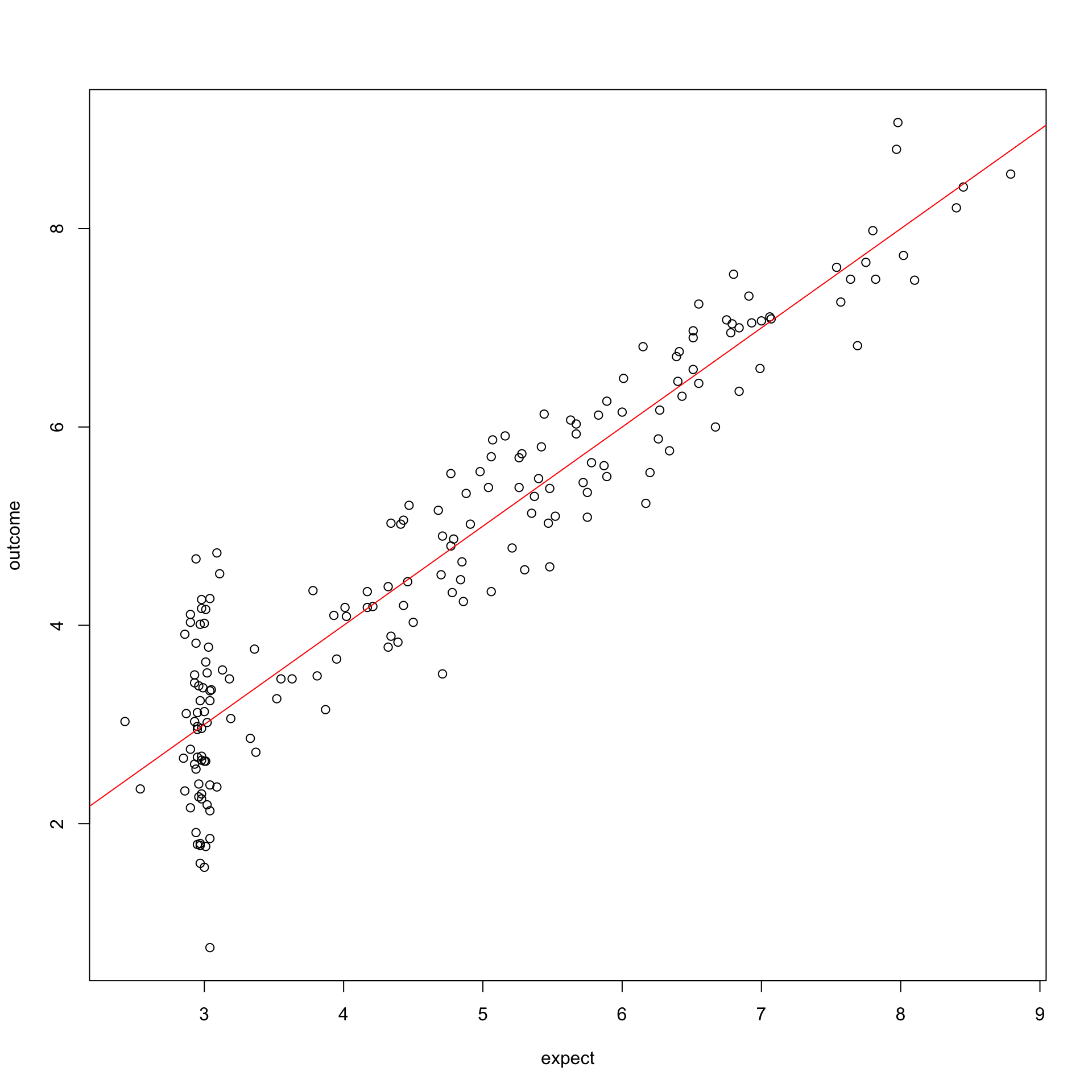
\[\LARGE \eta^2\]
Squared correlation between model expectation and actual outcome: 0.873
Proportion of:
- explained / total variance
- model / total variance
- between group variance / total variance.
\(\frac{489.613}{560.567} = 0.873\)
Contact

![]()